
рекомендации по выбору прибора и схема подключения к проводке в электрощитке
Автоматические выключатели используются для подачи электроэнергии в цепь и ее обесточивания в автоматическом режиме при возникновении неисправностей.
- Особенности конструкции
- Критерии выбора
- Номинальный электроток
- Время-токовая характеристика
- Рекомендации по подключению
Чаще всего они монтируются в распределительных щитках и обеспечивают защиту электроцепи от перегрузок.
Чтобы правильно выбрать и подключить автомат, необходимо разбираться в конструкции и технических характеристиках устройства.
Особенности конструкции
Автоматический выключатель представляет собой довольно сложное электромеханическое устройство. Некоторые современные модели оснащены блоками электронного управления. Но чтобы грамотно подключить автомат в щитке, достаточно разобраться с конструкцией классического прибора. Именно такой вид оборудования чаще всего используется в быту.
В верхней части устройства расположена входная клемма, жестко соединенная с неподвижным контактом. Нижняя клемма подсоединена к биметаллической пластине, выполняющей функцию теплового разъединителя. Также в состав автомата входит соленоид. Один из его контактов подключен к биметаллической пластинке, а второй – к подвижному контакту.
В механизме разъединителя подвижный контакт надежно зафиксирован с помощью пружины не только в выключенном, но и во включенном состоянии. Благодаря этому достигается быстрая коммутация, а также исключается сильный нагрев контактов при дуговом либо искровом разряде, который может появиться в момент разрыва электроцепи. Механизм разъединения может сработать в следующих ситуациях:
- При включении или отключении автомата вручную.
- Когда в цепи ток превышает номинальный показатель, нагревается биметаллическая пластина. В результате она изгибается и воздействует на рычаг разъединительного механизма.
- При возникновении в электроцепи короткого замыкания в соленоиде под воздействием тока индуцируется магнитный поток.
 Сердечник соленоида втягивается и, воздействуя на подвижный контакт, отключает цепь.
Сердечник соленоида втягивается и, воздействуя на подвижный контакт, отключает цепь.
Все автоматические выключатели оснащаются дугогасительной камерой. Она содержит хорошо изолированные друг от друга медные либо стальные пластинки. Появление дугового разряда сопровождается образованием сильного магнитного поля. Оно индуцирует в пластинах ЭДС, которое также создает собственное поле, имеющее противоположный заряд.
Благодаря взаимодействию двух полей дуговой разряд втягивается в пластинки, которые делят дугу на части и охлаждают ее.
Также в камере находится отверстие для выхода газов, образующихся в момент горения дугового разряда. Именно из-за появления электродуги при частых срабатываниях автоматического выключателя его контакты могут подгореть.
Критерии выбора
Перед тем как подключить автомат к проводке, необходимо правильно выбрать устройство.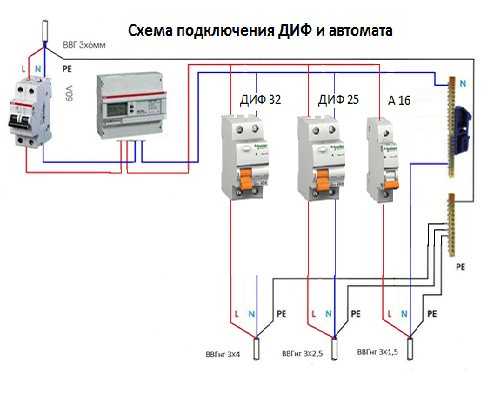 Безусловно, предпочтение стоит отдавать продукции известных брендов. Также важное значение имеет показатель номинального тока и частоты сети. Однако есть и другие характеристики, на которые следует обратить внимание при выборе прибора.
Безусловно, предпочтение стоит отдавать продукции известных брендов. Также важное значение имеет показатель номинального тока и частоты сети. Однако есть и другие характеристики, на которые следует обратить внимание при выборе прибора.
Номинальный электроток
Это один из важнейших параметров автоматов, показывающий максимальный ток, который может длительное время проходить через прибор без его срабатывания.
Когда показатель электротока превышает номинальный на 13%, включается тепловой разъединитель.
Необходимо помнить, что номинальный электроток всегда должен соответствовать сечению проводников в защищаемой цепи, а не мощности нагрузки. Чтобы гарантировать правильную работу автомата и избежать перегрева проводки, нужно следовать двум правилам:
- Сечение проводников подбирается в соответствии с предполагаемой нагрузкой в сети.
- Номинальный показатель электротока автомата выбирается в зависимости от сечения проводов.

Таким образом, автоматический выключатель не позволяет использовать все возможности проводников, а необходим для их ограничения. Это сделано намеренно, чтобы проводка не перегревалась.
Время-токовая характеристика
Для отображения время-токовой характеристики (ВТХ) используется буквенный индекс. В маркировке всех автоматов он стоит перед показателем номинального электротока. Чтобы разобраться с этой характеристикой и ее влиянием на работу автоматического выключателя, следует изучить график.
На нем отображена зависимость времени срабатывания прибора от кратности протекающего электротока к номинальному. На графике хорошо видно, что с увеличением кратности повышается и скорость срабатывания прибора. Самыми быстрыми являются приборы категории B, а медленными — D. Кроме этого, выпускаются устройства категорий Z и K, но они в быту не используются.
Также следует помнить, что график составлен для автоматов, работающих при температуре внешней среды до +30 °C.
Опытные электрики используют те модели щитков, в которых после монтажа всей аппаратуры остается достаточно свободного пространства.
Выбирая модель автомата, необходимо ориентироваться на характер нагрузки. Для нормальной работы розеточных сетей и светильников (активной нагрузки) вполне достаточно использовать приборы категории B. Однако в каждой квартире есть холодильник и стиральная машина (реактивная нагрузка), а эти агрегаты требуют монтажа автоматов категории C.
Чаще всего в квартирах устанавливаются именно такие приборы. Но идеальным вариантом является установка устройств категории B и C. Например, к цепи освещения подключается автомат категории В, установленный в квартире.
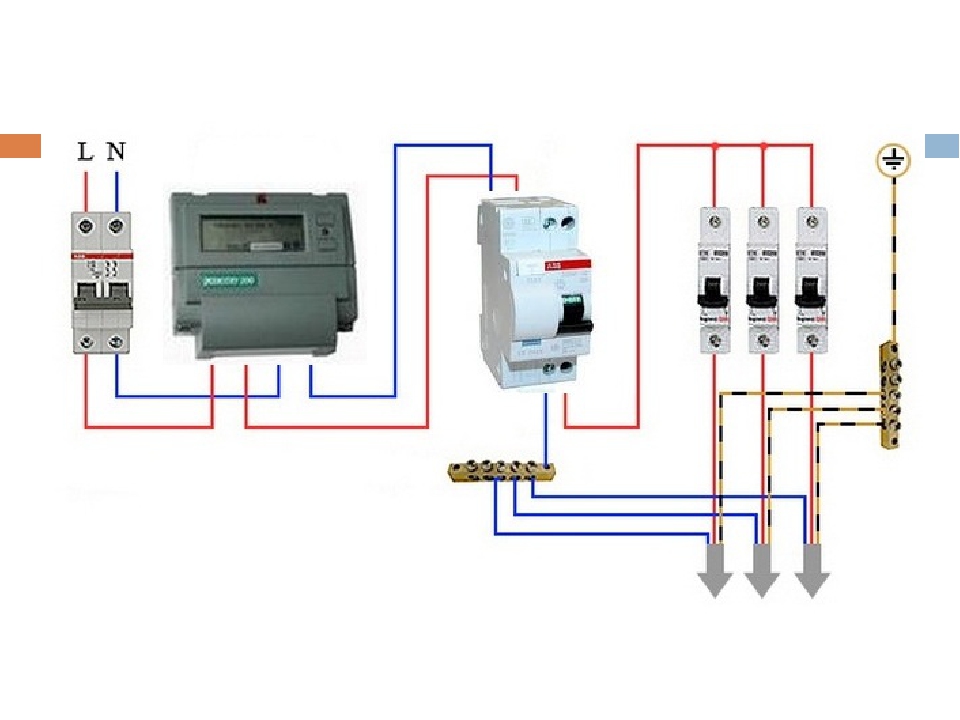
Рекомендации по подключению
Особенность подключения автоматов в щитке заключается в том, что проводники необходимо соединить с нужными контактами. Кабель питания должен быть подсоединен к неподвижным контактам. Так как приборы этого типа могут иметь различное количество полюсов, то стоит рассмотреть две наиболее часто используемые схемы подключения автоматов.
Для монтажа прибора применяется DIN-рейка. Если необходимо подключить однополюсной автомат, то к верхней клемме подсоединяется фаза с устройства УЗО либо вводного аппарата. Нижняя клемма соединяется с защищаемой электроцепью.
Чтобы правильно подключить в электрическом щите автоматы с двумя полюсами, к левой верхней клемме нужно подсоединить фазу, а на правую установить нулевой проводник.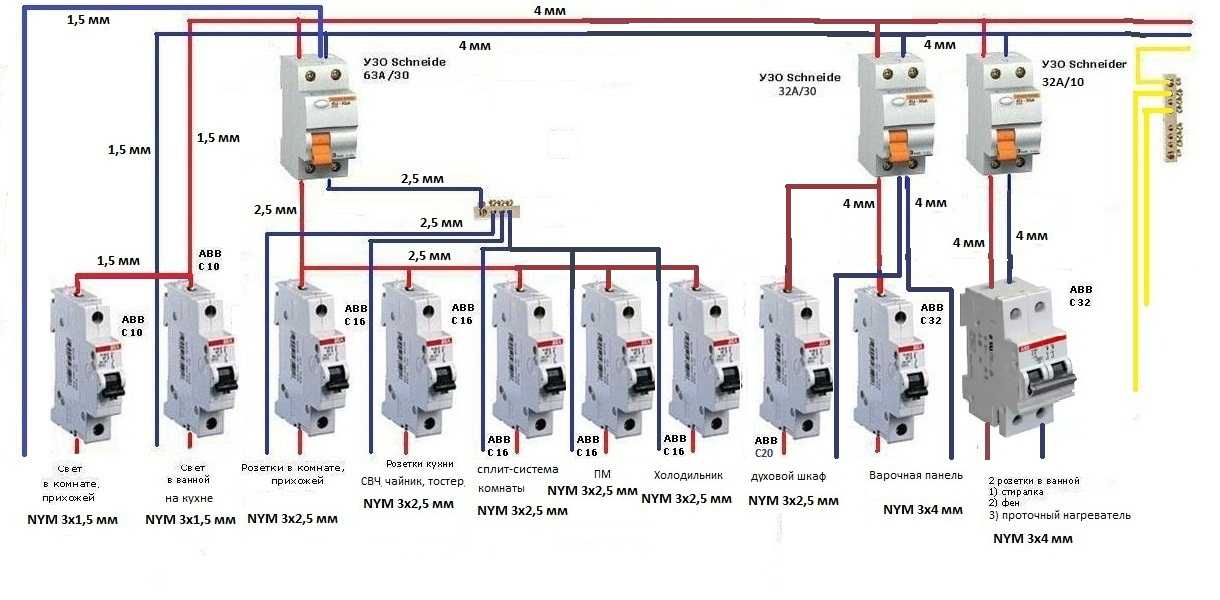 С нижнего левого контакта фазный провод уходит в электроцепь, а к правой подключается ноль. Также следует помнить, что сильно затягивать прижимные винты клемм нельзя, так как можно повредить корпус прибора.
С нижнего левого контакта фазный провод уходит в электроцепь, а к правой подключается ноль. Также следует помнить, что сильно затягивать прижимные винты клемм нельзя, так как можно повредить корпус прибора.
Когда все работы по подключению автомата будут завершены, необходимо подать на электрощиток напряжение и с помощью тестера проверить наличие тока на входе и выходе устройства. Перед началом подключения автомата нужно оценить свои возможности.
Хотя это не самый сложный процесс, в некоторых ситуациях работу стоит доверить профессионалам.
Как правильно подключить автомат, сверху или снизу, и в чем разница?
Главная » Ремонт и стройка
Ремонт и стройка
На чтение 2 мин.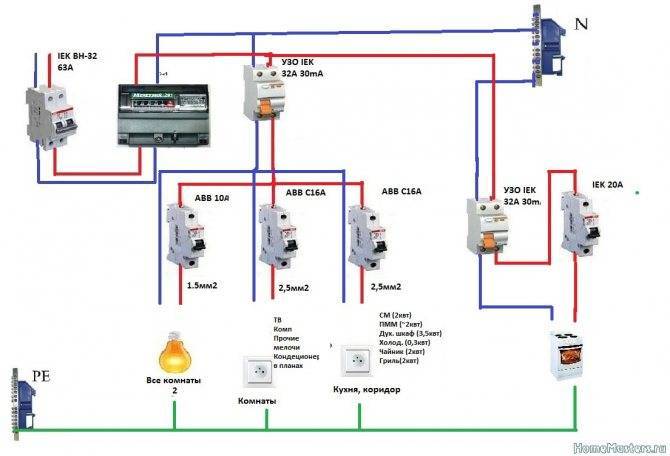 Просмотров 4.1k.
Просмотров 4.1k.
Начинающие электрики, зачастую не знают, как правильно подключить автомат сверху или снизу. Они просто не видят в чем разница, и есть ли она на самом деле.
Как подать питание на автомат?
При подключении современной бытовой модели не имеет большого значения, будет ввод в автомат сверху или снизу.
Путаница с поиском правильного решения возникла по двум причинам:
Верхние контакты были неподвижны, а сам корпус разборной (для обслуживания, чистки контактов и т.п.). В этом случае любой электрик знал, что верхние неподвижные контакты всегда под напряжением. Это был просто вопрос безопасности.
Современные вводные автоматы имеют совершенно иной вид. Их корпус может открываться лишь единожды — при подключении аппарата.
В случае неисправности такие устройства не ремонтируют, а меняют целиком.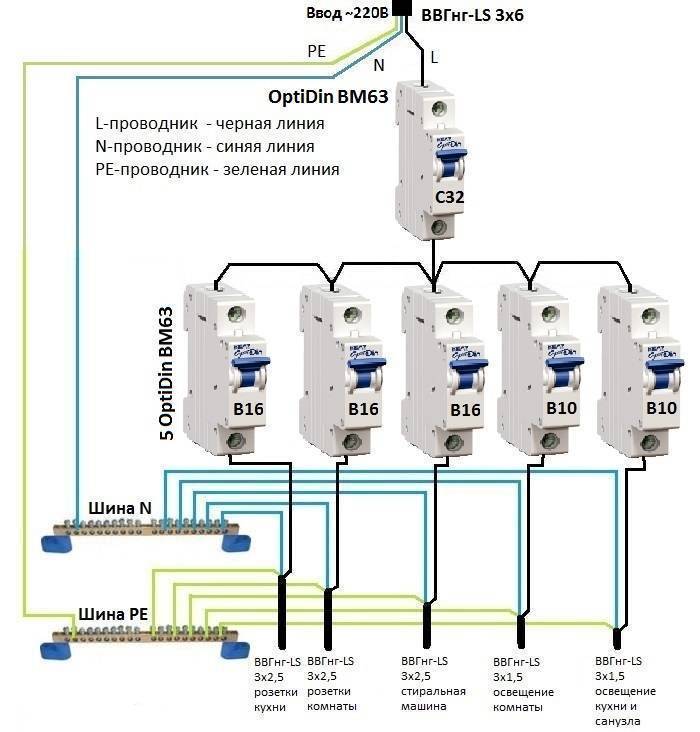 Поэтому здесь значения не имеет, как будет осуществлено подключение автомата в щитке — вряд ли кто-то будет его разбирать (вероятность травмирования минимальна).
Поэтому здесь значения не имеет, как будет осуществлено подключение автомата в щитке — вряд ли кто-то будет его разбирать (вероятность травмирования минимальна).
- Есть ряд специальных устройств, которые устанавливаются в комплекте с автоматом, например, УЗО.
Вот для них правильное подключение имеет огромное значение. Но на корпус таких агрегатов обычно нанесена схема, в которой указаны точки для присоединения входа автомата и т.д.
И хотя, для самого автоматического выключателя не имеет значения, как будет подведен ток, споры между электриками ведутся до сих пор.
Мастера старой закалки, размахивая ПУЭ, настаивают на подключении исключительно сверху.
Вот только эта, без сомнения, полезная книга была издана еще во времена Советского Союза. Ее регулярно переиздают, но поправки в текст практически не вносятся. Большинство требований и нормативов остаются ориентированными на аппараты практически полувековой давности.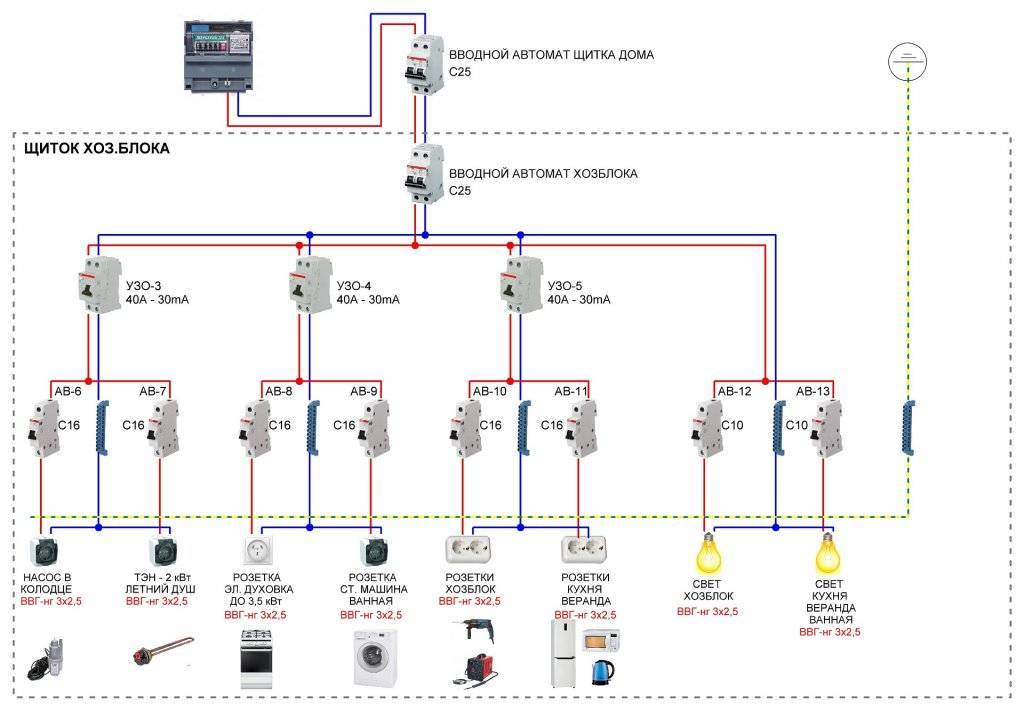
Так, можно ли подключать автомат снизу-вверх?
Среди профессиональных электриков считается хорошим тоном подключение автоматического выключателя именно сверху. Аппараты, подсоединенные снизу, они считают работой дилетантов-самоучек. Хотя на эксплуатации устройства и функционировании остальных приборов это никак не отражается.
Поэтому на всех промышленных объектах, в общественных местах и серьезных организациях все подобные аппараты подключены именно сверху.
Если же речь идет о прокладке электричества в собственной квартире или на любимой даче (где всей электрикой занимается хозяин дома, и никто кроме него там работать не будет), то можно делать так, как удобнее.
Но, если есть вероятность забыть или запутаться, то лучше (в целях собственной безопасности) все автоматические выключатели подключать сверху.
Учебное пособие по машинному обучению с примерами
Примечание редактора. Эта статья была обновлена нашей редакцией 12. 09.22. Он был изменен, чтобы включить последние источники и привести его в соответствие с нашими текущими редакционными стандартами.
09.22. Он был изменен, чтобы включить последние источники и привести его в соответствие с нашими текущими редакционными стандартами.
Машинное обучение (ML) вступает в свои права, с растущим признанием того, что ML может играть ключевую роль в широком спектре критически важных приложений, таких как интеллектуальный анализ данных, обработка естественного языка, распознавание изображений и экспертные системы. Машинное обучение предоставляет потенциальные решения во всех этих и многих других областях и, вероятно, станет опорой нашей будущей цивилизации.
Предложение опытных дизайнеров машинного обучения еще не удовлетворило этот спрос. Основная причина этого заключается в том, что ML просто сложна. Этот учебник по машинному обучению знакомит с базовой теорией, излагает общие темы и концепции, а также упрощает следование логике и ознакомление с основами машинного обучения.
Основы машинного обучения: что такое машинное обучение?
Так что же такое «машинное обучение»? ML это лот вещей. Область обширна и быстро расширяется, постоянно разделяясь и подразделяясь на различные подспециальности и типы машинного обучения.
Область обширна и быстро расширяется, постоянно разделяясь и подразделяясь на различные подспециальности и типы машинного обучения.
Тем не менее, есть несколько основных общих черт, и общую тему лучше всего резюмирует это часто цитируемое заявление, сделанное Артуром Сэмюэлем еще в 1959 году: «[Машинное обучение — это] область исследования, которая дает компьютерам возможность учиться без явного программирования».
В 1997 году Том Митчелл предложил «хорошо сформулированное» определение, которое оказалось более полезным для инженеров: «Говорят, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, измеряемом P, улучшается с опытом E».
«Говорят, что компьютерная программа учится на опыте E в отношении некоторой задачи T и некоторого показателя производительности P, если ее производительность на T, измеряемая P, улучшается с опытом E». — Том Митчелл, Университет Карнеги-Меллона.
Итак, если вы хотите, чтобы ваша программа предсказывала, например, схемы движения на оживленном перекрестке (задача T), вы можете запустить ее через алгоритм машинного обучения с данными о прошлых схемах движения (опыт E) и, если она успешно «обученный», тогда он будет лучше прогнозировать будущие модели трафика (показатель эффективности P)9.0005
Очень сложная природа многих реальных проблем, однако, часто означает, что изобретение специализированных алгоритмов, которые каждый раз будут решать их идеально, нецелесообразно, если не невозможно.
Реальные примеры проблем машинного обучения включают: «Это рак?», «Какова рыночная стоимость этого дома?», «Кто из этих людей дружит друг с другом?», «Взорвется ли этот ракетный двигатель?» при взлете?», «Понравится ли этому человеку этот фильм?», «Кто это?», «Что ты сказал?» и «Как ты управляешь этой штукой?» Все эти проблемы — отличные цели для проекта машинного обучения; на самом деле машинное обучение применялось к каждому из них с большим успехом.
ML решает задачи, которые невозможно решить только числовыми средствами.
Среди различных типов задач машинного обучения проводится важное различие между контролируемым и неконтролируемым обучением:
- Контролируемое машинное обучение — это когда программа «обучается» на предварительно определенном наборе «обучающих примеров», которые затем облегчают ее способность делать точные выводы при получении новых данных.
- Неконтролируемое машинное обучение — это когда программе предоставляется набор данных, и она должна найти в них закономерности и взаимосвязи.
Здесь мы сосредоточимся в первую очередь на обучении с учителем, но последняя часть статьи включает краткое обсуждение обучения без учителя с некоторыми ссылками для тех, кто заинтересован в изучении этой темы.
Машинное обучение с учителем
В большинстве приложений для обучения с учителем конечной целью является разработка точно настроенной функции предсказания h(x) (иногда называемой «гипотезой»). «Обучение» состоит в использовании сложных математических алгоритмов для оптимизации этой функции таким образом, чтобы при заданных входных данных x об определенной области (скажем, площади дома) она точно предсказывала некоторое интересное значение h(x) (скажем, рыночную цену). для указанного дома).
«Обучение» состоит в использовании сложных математических алгоритмов для оптимизации этой функции таким образом, чтобы при заданных входных данных x об определенной области (скажем, площади дома) она точно предсказывала некоторое интересное значение h(x) (скажем, рыночную цену). для указанного дома).
На практике x почти всегда представляет несколько точек данных. Так, например, предиктор цен на жилье может учитывать не только квадратные метры (x1), но также количество спален (x2), количество ванных комнат (x3), количество этажей (x4), год постройки (x5), почтовый индекс ( х6) и так далее. Определение того, какие входные данные использовать, является важной частью проектирования машинного обучения. Однако для пояснения проще всего принять одно входное значение.
Допустим, наш простой предиктор имеет следующую форму:
где и константы. Наша цель — найти идеальные значения и заставить наш предиктор работать как можно лучше.
Оптимизация предиктора h(x) выполняется с использованием обучающих примеров . Для каждого обучающего примера у нас есть входное значение
Для каждого обучающего примера у нас есть входное значение x_train , для которого заранее известен соответствующий выход y . Для каждого примера мы находим разницу между известным правильным значением y и нашим предсказанным значением 9.0059 ч(x_train) . С достаточным количеством обучающих примеров эти различия дают нам полезный способ измерить «неправильность» h(x) . Затем мы можем настроить h(x) , изменив значения и, чтобы сделать его «менее неправильным». Этот процесс повторяется до тех пор, пока система не сойдется к лучшим значениям для и . Таким образом, предсказатель обучается и готов делать реальные предсказания.
Примеры машинного обучения
Мы используем простые задачи для иллюстрации, но ML существует потому, что в реальном мире задачи намного сложнее. На этом плоском экране мы можем представить изображение не более чем трехмерного набора данных, но задачи машинного обучения часто имеют дело с данными с миллионами измерений и очень сложными предикторными функциями. ML решает проблемы, которые невозможно решить только численными средствами.
ML решает проблемы, которые невозможно решить только численными средствами.
Имея это в виду, давайте рассмотрим еще один простой пример. Допустим, у нас есть следующие обучающие данные, в которых сотрудники компании оценили свою удовлетворенность по шкале от 1 до 100:
Во-первых, обратите внимание, что данные немного зашумлены. То есть, хотя мы видим, что в этом есть закономерность (т. е. удовлетворенность сотрудников имеет тенденцию расти по мере роста заработной платы), не все они четко укладываются в прямую линию. Это всегда будет иметь место с реальными данными (и мы абсолютно хотим обучить нашу машину, используя данные реального мира). Как мы можем научить машину точно предсказывать уровень удовлетворенности сотрудников? Ответ, конечно же, что мы не можем. Цель ML никогда не состоит в том, чтобы делать «идеальные» предположения, потому что ML имеет дело с областями, где таких вещей нет. Цель состоит в том, чтобы делать предположения, которые достаточно хороши, чтобы быть полезными.
Чем-то напоминает известное высказывание Джорджа Э. П. Бокса, британского математика и профессора статистики: «Все модели ошибочны, но некоторые из них полезны».
Цель машинного обучения никогда не состоит в том, чтобы делать «идеальные» предположения, потому что машинное обучение имеет дело с областями, где таких вещей нет. Цель состоит в том, чтобы делать предположения, которые достаточно хороши, чтобы быть полезными.
Машинное обучение в значительной степени основано на статистике. Например, когда мы обучаем нашу машину обучению, мы должны предоставить ей статистически значимую случайную выборку в качестве обучающих данных. Если обучающий набор не является случайным, мы рискуем получить шаблоны машинного обучения, которых на самом деле нет. И если обучающая выборка слишком мала (см. закон больших чисел), мы не научимся и даже можем прийти к неточным выводам. Например, попытка предсказать модели удовлетворенности в масштабах всей компании на основе данных только от высшего руководства, скорее всего, будет подвержена ошибкам.
С этим пониманием давайте дадим нашей машине данные, которые мы дали выше, и заставим ее изучить их. Сначала мы должны инициализировать наш предиктор h(x) с некоторыми разумными значениями и . Теперь, когда мы помещаем его в обучающую выборку, наш предиктор выглядит так:
Если мы спросим этот предиктор об удовлетворенности сотрудника, зарабатывающего 60 000 долларов, он предскажет рейтинг 27:
Очевидно, что это ужасная догадка и что эта машина не знает очень многого.
Теперь давайте дадим этому предсказателю все зарплаты из нашей обучающей выборки и отметим разницу между полученными прогнозируемыми рейтингами удовлетворенности и фактическими рейтингами удовлетворенности соответствующих сотрудников. Если мы проделаем небольшое математическое волшебство (которое я опишу позже в статье), мы сможем с очень высокой степенью уверенности рассчитать, что значения 13,12 для и 0,61 для дадут нам лучший предиктор.
И если мы повторим этот процесс, скажем, 1500 раз, наш предсказатель будет выглядеть так:
В этот момент, если мы повторим процесс, мы обнаружим это и больше не изменимся сколько-нибудь заметно, и, таким образом, мы увидим, что система сошлась. Если мы не допустили ошибок, значит, мы нашли оптимальный предиктор. Соответственно, если теперь мы снова спросим у машины рейтинг удовлетворенности сотрудника, который зарабатывает 60 000 долларов, он предскажет оценку ~60.
Теперь мы кое к чему пришли.
Регрессия машинного обучения: примечание о сложности
Приведенный выше пример технически представляет собой простую задачу одномерной линейной регрессии, которую в действительности можно решить, выведя простое нормальное уравнение и полностью пропустив этот процесс «настройки». Однако рассмотрим предсказатель, который выглядит следующим образом:
Эта функция принимает входные данные в четырех измерениях и имеет множество полиномиальных членов. Вывод нормального уравнения для этой функции является серьезной проблемой. Многие современные задачи машинного обучения требуют тысяч или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов. Прогнозирование того, как будет выражен геном организма или каким будет климат через 50 лет, — примеры таких сложных задач.
Вывод нормального уравнения для этой функции является серьезной проблемой. Многие современные задачи машинного обучения требуют тысяч или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов. Прогнозирование того, как будет выражен геном организма или каким будет климат через 50 лет, — примеры таких сложных задач.
Многие современные задачи машинного обучения требуют тысяч или даже миллионов измерений данных для построения прогнозов с использованием сотен коэффициентов.
К счастью, итеративный подход, используемый системами машинного обучения, гораздо более устойчив к такой сложности. Вместо грубой силы система машинного обучения «чувствует» путь к ответу. Для больших задач это работает намного лучше. Хотя это не означает, что машинное обучение может решить все сколь угодно сложные проблемы — нет, — оно делает его невероятно гибким и мощным инструментом.
Градиентный спуск: минимизация «неправильности»
Давайте подробнее рассмотрим, как работает этот итеративный процесс.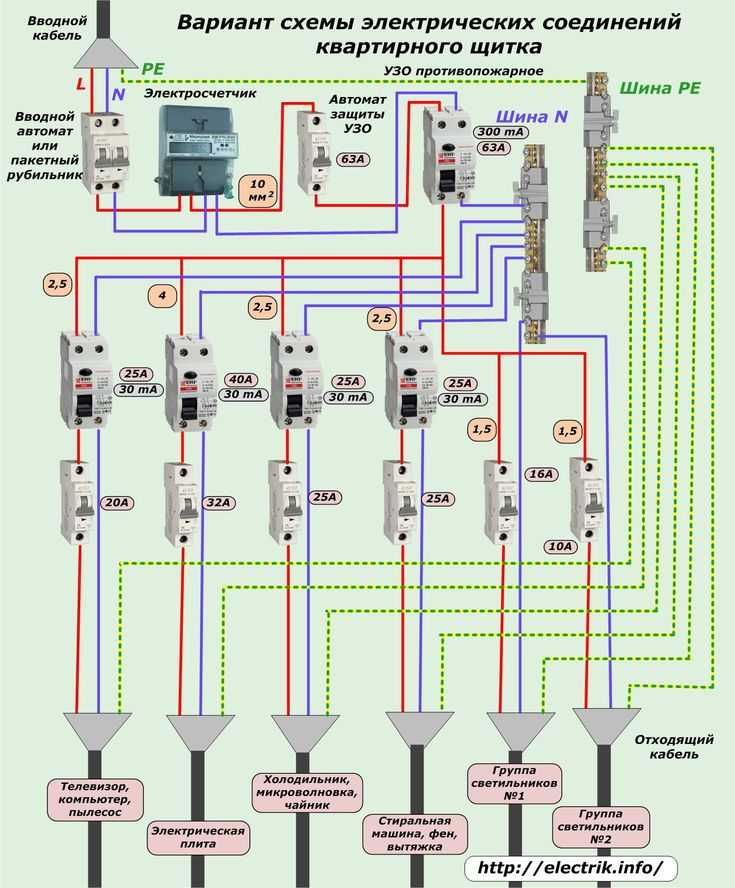 Как в приведенном выше примере убедиться, что с каждым шагом мы становимся лучше, а не хуже? Ответ заключается в нашем «измерении неправильности», а также в небольшом расчете. (Это «математическое волшебство», упомянутое ранее.)
Как в приведенном выше примере убедиться, что с каждым шагом мы становимся лучше, а не хуже? Ответ заключается в нашем «измерении неправильности», а также в небольшом расчете. (Это «математическое волшебство», упомянутое ранее.)
Мера неправильности известна как функция стоимости (она же функция потерь ), . Входные данные представляют все коэффициенты, которые мы используем в нашем предсказателе. В нашем случае это действительно пара и . дает нам математическое измерение ошибочности нашего предиктора, когда он использует заданные значения и .
Выбор функции стоимости — еще одна важная часть программы ML. В разных контекстах быть «неправильным» может означать очень разные вещи. В нашем примере с удовлетворенностью сотрудников хорошо зарекомендовавшим себя стандартом является линейная функция наименьших квадратов:
. очень «строгое» измерение неправильности. Функция стоимости вычисляет средний штраф по всем обучающим примерам.
Теперь мы видим, что наша цель состоит в том, чтобы найти и для нашего предиктора h(x) такие, чтобы наша функция стоимости была как можно меньше. Для этого мы призываем силу исчисления.
Рассмотрим следующий график функции стоимости для некоторой конкретной задачи машинного обучения:
Здесь мы можем увидеть стоимость, связанную с различными значениями и . Мы видим, что форма графика имеет небольшую чашу. Дно чаши представляет собой наименьшую стоимость, которую наш предиктор может дать нам на основе данных обучения. Цель состоит в том, чтобы «скатиться с горки» и найти соответствующую этой точке точку.
Здесь в этом учебнике по машинному обучению появляется исчисление. Чтобы не усложнять объяснение, я не буду приводить здесь уравнения, но, по сути, мы берем градиент , который является парой производных от (одна над и одна над ). Градиент будет разным для каждого различного значения и и определяет «наклон холма» и, в частности, «какой путь вниз» для этих конкретных s. Например, когда мы подставляем наши текущие значения в градиент, он может сказать нам, что добавление небольшого количества к и небольшое вычитание приведет нас к дну долины функции стоимости. Поэтому прибавляем немного к , немного отнимаем от , и вуаля! Мы завершили один раунд нашего алгоритма обучения. Наш обновленный предиктор h(x) = + x будет возвращать лучшие прогнозы, чем раньше. Наша машина стала немного умнее.
Например, когда мы подставляем наши текущие значения в градиент, он может сказать нам, что добавление небольшого количества к и небольшое вычитание приведет нас к дну долины функции стоимости. Поэтому прибавляем немного к , немного отнимаем от , и вуаля! Мы завершили один раунд нашего алгоритма обучения. Наш обновленный предиктор h(x) = + x будет возвращать лучшие прогнозы, чем раньше. Наша машина стала немного умнее.
Этот процесс чередования вычисления текущего градиента и обновления s по результатам известен как градиентный спуск.
Это охватывает базовую теорию, лежащую в основе большинства контролируемых систем машинного обучения. Но базовые концепции можно применять по-разному, в зависимости от решаемой проблемы.
Проблемы классификации в машинном обучении
В контролируемом машинном обучении есть две основные подкатегории:
- Системы регрессионного машинного обучения — Системы, в которых прогнозируемое значение находится где-то в непрерывном спектре.
 Эти системы помогают нам с вопросами «Сколько?» или «Сколько?»
Эти системы помогают нам с вопросами «Сколько?» или «Сколько?» - Классификация систем машинного обучения — Системы, в которых мы ищем прогноз «да» или «нет», например «Является ли эта опухоль раковой?», «Соответствует ли это печенье нашим стандартам качества?» и так далее.
Как оказалось, основная теория машинного обучения более или менее одинакова. Основные отличия заключаются в конструкции предиктора h(x) и дизайн функции стоимости.
До сих пор наши примеры были сосредоточены на проблемах регрессии, поэтому теперь давайте рассмотрим пример классификации.
Вот результаты исследования качества файлов cookie, где все обучающие примеры были помечены как «хорошие файлы cookie» ( y = 1 ) синим цветом или «плохие файлы cookie» ( y = 0 ) красным цветом. .
В классификации предиктор регрессии не очень полезен. Обычно нам нужен предсказатель, который делает предположение где-то между 0 и 1. В классификаторе качества файлов cookie прогноз 1 будет представлять очень уверенное предположение о том, что печенье идеальное и очень аппетитное. Прогноз 0 означает высокую степень уверенности в том, что файл cookie является помехой для индустрии файлов cookie. Значения, попадающие в этот диапазон, представляют меньшую достоверность, поэтому мы можем спроектировать нашу систему таким образом, чтобы прогноз 0,6 означал: «Чувак, это трудный выбор, но я соглашусь с да, вы можете продать это печенье», а значение точно в середине, на уровне 0,5, может означать полную неопределенность. Это не всегда то, как доверие распределяется в классификаторе, но это очень распространенный дизайн, и он подходит для целей нашей иллюстрации.
В классификаторе качества файлов cookie прогноз 1 будет представлять очень уверенное предположение о том, что печенье идеальное и очень аппетитное. Прогноз 0 означает высокую степень уверенности в том, что файл cookie является помехой для индустрии файлов cookie. Значения, попадающие в этот диапазон, представляют меньшую достоверность, поэтому мы можем спроектировать нашу систему таким образом, чтобы прогноз 0,6 означал: «Чувак, это трудный выбор, но я соглашусь с да, вы можете продать это печенье», а значение точно в середине, на уровне 0,5, может означать полную неопределенность. Это не всегда то, как доверие распределяется в классификаторе, но это очень распространенный дизайн, и он подходит для целей нашей иллюстрации.
Оказывается, есть хорошая функция, которая хорошо фиксирует это поведение. Это называется сигмовидной функцией, g(z) , и выглядит примерно так:
z — некоторое представление наших входных данных и коэффициентов, например: :
Обратите внимание, что сигмовидная функция преобразует наши выходные данные в диапазон от 0 до 1.
Логика построения функции стоимости также различается по классификации. Мы снова спрашиваем: «Что значит, если догадка ошибочна?» и на этот раз очень хорошее эмпирическое правило заключается в том, что если правильное предположение было 0, а мы угадали 1, то мы были полностью неправы, и наоборот. Поскольку нельзя быть более неправым, чем полностью неправым, наказание в этом случае огромно. В качестве альтернативы, если правильное предположение было 0, а мы угадали 0, наша функция стоимости не должна добавлять никаких затрат каждый раз, когда это происходит. Если предположение было правильным, но мы не были полностью уверены (например, y = 1 , но h(x) = 0,8 ), это должно стоить немного, и если наше предположение было неверным, но мы не были полностью уверены (например, y = 1 , но h( x) = 0,3 ), это должно быть сопряжено со значительными затратами, но не такими большими, как если бы мы были полностью неправы.
Это поведение фиксируется функцией журнала, так что:
Опять же, функция стоимости дает нам среднюю стоимость по всем нашим обучающим примерам.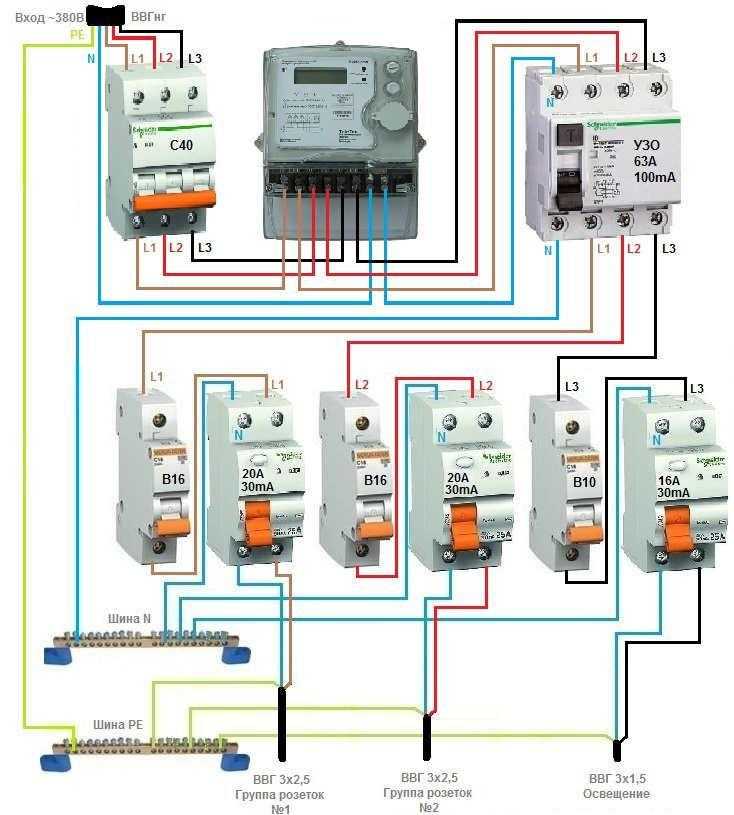
Итак, здесь мы описали, как предиктор h(x) и функция стоимости различаются между регрессией и классификацией, но градиентный спуск по-прежнему работает нормально.
Предиктор классификации можно визуализировать, нарисовав граничную линию; т. е. барьер, при котором прогноз изменяется с «да» (прогноз больше 0,5) на «нет» (прогноз меньше 0,5). При хорошо спроектированной системе наши данные о файлах cookie могут генерировать границу классификации, которая выглядит следующим образом:
Теперь это машина, которая кое-что знает о файлах cookie!
Введение в нейронные сети
Обсуждение машинного обучения было бы неполным без упоминания хотя бы нейронных сетей. Нейронные сети не только предлагают чрезвычайно мощный инструмент для решения очень сложных проблем, они также предлагают увлекательные намеки на работу нашего собственного мозга и интригующие возможности для создания действительно интеллектуальных машин за один день.
Нейронные сети хорошо подходят для моделей машинного обучения, где количество входных данных огромно.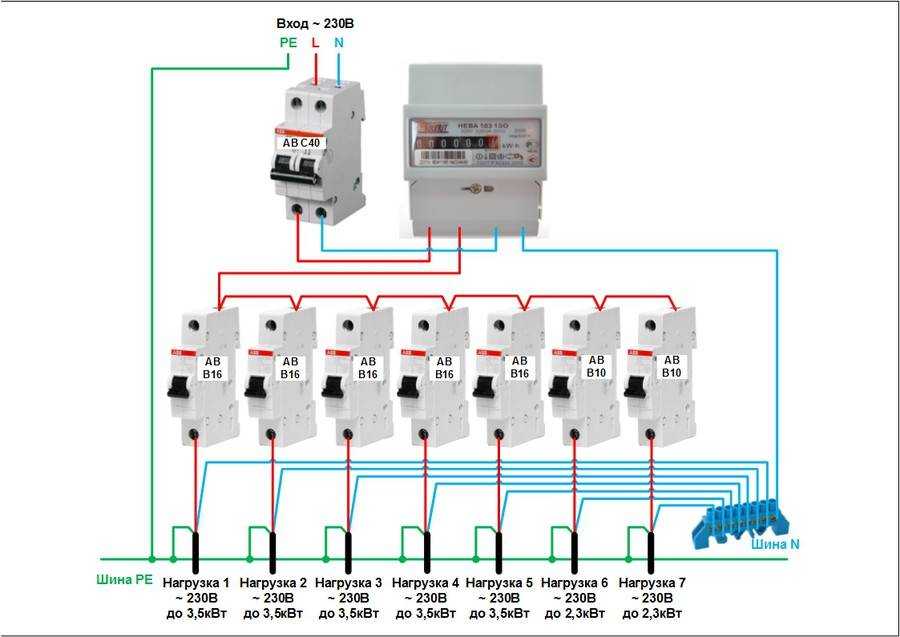 Вычислительные затраты на решение такой задачи слишком велики для типов систем, которые мы обсуждали. Однако оказывается, что нейронные сети можно эффективно настраивать с помощью методов, которые в принципе поразительно похожи на градиентный спуск.
Вычислительные затраты на решение такой задачи слишком велики для типов систем, которые мы обсуждали. Однако оказывается, что нейронные сети можно эффективно настраивать с помощью методов, которые в принципе поразительно похожи на градиентный спуск.
Подробное обсуждение нейронных сетей выходит за рамки этого руководства, но я рекомендую ознакомиться с предыдущим постом на эту тему.
Неконтролируемое машинное обучение
Неконтролируемое машинное обучение обычно направлено на поиск взаимосвязей в данных. В этом процессе не используются обучающие примеры. Вместо этого системе дается набор данных и ставится задача найти в них закономерности и корреляции. Хороший пример — выявление сплоченных групп друзей в данных социальных сетей.
Алгоритмы машинного обучения, используемые для этого, сильно отличаются от тех, которые используются для обучения с учителем, и эта тема заслуживает отдельного сообщения. Однако, чтобы тем временем что-то пожевать, взгляните на алгоритмы кластеризации, такие как k-средние, а также изучите системы уменьшения размерности, такие как анализ основных компонентов. Вы также можете прочитать нашу статью о полуконтролируемой классификации изображений.
Применение теории на практике
Мы рассмотрели большую часть базовой теории, лежащей в основе области машинного обучения, но, конечно, мы коснулись только самой поверхности.
Имейте в виду, что для реального применения теорий, содержащихся в этом введении, к реальным примерам машинного обучения необходимо гораздо более глубокое понимание этих тем. В машинном обучении есть много тонкостей и ловушек, а также множество способов сбиться с пути того, что кажется отлично настроенной мыслящей машиной. Почти с каждой частью базовой теории можно играть и изменять бесконечно, и результаты часто бывают ошеломляющими. Многие вырастают в совершенно новые области исследований, которые лучше подходят для решения конкретных проблем.
Очевидно, что машинное обучение — невероятно мощный инструмент. В ближайшие годы он обещает помочь решить некоторые из наших самых насущных проблем, а также открыть совершенно новые возможности для фирм, занимающихся наукой о данных. Спрос на инженеров по машинному обучению будет только расти, предлагая невероятные шансы стать частью чего-то большого. Надеюсь, вы подумаете о том, чтобы принять участие в акции!
Благодарность
Эта статья основана на материалах, преподаваемых профессором Стэнфордского университета доктором Эндрю Нг в его бесплатном и открытом курсе «Машинное обучение с учителем». Он подробно описывает все, что обсуждается в этой статье, и дает множество практических советов специалистам по машинному обучению. Я не могу рекомендовать его достаточно высоко для тех, кто заинтересован в дальнейшем изучении этой увлекательной области.
Связанные:
- Звуковая логика и монотонные модели искусственного интеллекта
- Schooling Flappy Bird: учебное пособие с подкреплением
- Начало работы с TensorFlow: руководство по машинному обучению
- Прогнозирование машинного обучения Python с помощью Flask REST API
- Методы ансамбля: чемпион Kaggle по машинному обучению
Краткое введение в машинное обучение
В этой статье я кратко расскажу вам о машинном обучении.
Вот краткое содержание, которое даст вам общее представление о статье. Если вы хотите прочитать о чем-то конкретном, просто нажмите на ссылку, и вы перейдете к этому разделу руководства.
Содержание:
- Что за машинное обучение?
- Примеры использования машинного обучения сегодня
- Как работает машинное обучение
- Процесс построения модели
- Различные методы машинного обучения
Конечно, если вы новичок в науке о данных в целом и машинном обучении в частности, вам, вероятно, захочется прочитать всю статью. Вы получите гораздо лучший обзор, если прочитаете все, от начала до конца.
Хорошо… приступим.
Так что же такое машинное обучение?
Что за машинное обучение?
Если вы читали о науке о данных за последние несколько лет, вы, вероятно, слышали термин «машинное обучение». Машинное обучение стало очень популярным в техническом сообществе в целом и в науке о данных в частности.
Вы, наверное, уже слышали, что машинное обучение — это форма искусственного интеллекта. Это верно.
Но машинное обучение — это особый тип искусственного интеллекта.
В отличие от более старых форм ИИ, таких как системы, основанные на правилах, где программист жестко запрограммировал операторы IF/THEN, чтобы указать компьютеру, как себя вести, машинное обучение использует подход, в большей степени управляемый данными.
Машинное обучение: обучение компьютеров обучению на основе данных
Машинное обучение — это набор методов, позволяющих компьютерам учиться на основе данных.
Как я уже говорил ранее, большинство людей считают машинное обучение частью ИИ. Но, учитывая подход, основанный на данных, машинное обучение также имеет глубокие корни в статистике. Таким образом, машинное обучение находится на стыке науки о данных, искусственного интеллекта, статистики и информатики.
При этом утверждение о том, что машинное обучение позволяет компьютерам «учиться на данных», может показаться немного абстрактным. Возможно, будет легче понять, что такое машинное обучение, если посмотреть, как оно используется сегодня.
Примеры использования машинного обучения сегодня
Вы можете начать понимать, что такое машинное обучение, посмотрев, где и как оно используется. На самом деле он все чаще используется в широком спектре технологических продуктов.
Вот несколько примеров машинного обучения в нашей повседневной жизни:
- системы рекомендаций (на таких сайтах, как Amazon и Netflix)
- самоуправляемые автомобили
- классификация спама
Давайте кратко рассмотрим их.
Пример: Системы рекомендаций
Вы когда-нибудь задумывались о покупке чего-либо на Amazon и замечали на странице небольшой раздел под названием «Книги, которые могут вам понравиться» или «Другие товары, которые могут вам понравиться»?
Возможно, вы видели похожий раздел на главном экране Netflix под названием «Потому что вы смотрели…». Так что, если вы смотрели «Мстителей», этот раздел Netflix рекомендует другие фильмы , похожие на , или , связанные с Мстителями.
В широком смысле такие системы называются «рекомендательными системами», и они обычно строятся с использованием различных инструментов машинного обучения.
На высоком уровне эти системы «учатся» на ваших прошлых покупках и истории использования. У Amazon есть данные о ваших прошлых покупках, и они используют эти данные для создания системы машинного обучения, которая «узнает» то, что вам нравится. Узнав, что вам нравится, система машинного обучения может делать предложения (то есть прогнозы) о том, какие других предметов вам могут понравиться.
Пример: Самоуправляемые автомобили
Еще одно интересное применение машинного обучения — самоуправляемые автомобили.
Еще десять лет назад казалось бы невероятно футуристичным иметь автомобили, которые хоть немного могут управлять собой.
Но сегодня Tesla продаются с функцией «автопилота», которая позволяет автомобилю автоматически «рулить, ускоряться и тормозить» при определенных условиях.
Возможности этой функции самостоятельного вождения на данном этапе ограничены, но в некоторых случаях она работает.
Итак, как они использовали машинное обучение, чтобы сделать это?
Тесла и аналогичные автомобили оснащены датчиками, радарными системами и камерами. Эти камеры и датчики производят поток данных, который инженеры Tesla вводят в систему машинного обучения (в частности, в систему «глубокой нейронной сети»). Эта система машинного обучения «узнала» о различных дорожных особенностях, таких как автомобили, дорожные знаки, дорожная разметка и т. д., и узнала о соответствующих реакциях на различные дорожные особенности.
Данные поступают в систему, и система научилась оценивать и реагировать на различные события вождения.
Пример: классификация спама
Возможно, наиболее каноническим примером того, как машинное обучение используется в повседневной жизни, является спам-фильтр для вашей электронной почты.
Почти все современные почтовые клиенты, такие как Gmail от Google, имеют спам-фильтр.
Фильтр спама автоматически оценивает входящие сообщения электронной почты и пытается классифицировать любую «нежелательную» почту как «спам», после чего она отправляется в папку «Спам», поэтому вам не нужно ее видеть.
Это тоже построено с помощью машинного обучения.
Содержимое электронного письма — такие вещи, как слова, грамматика, заголовки, отправители — все можно рассматривать как формы данных. Компании электронной почты использовали исторические данные электронной почты для «обучения» систем машинного обучения. Эти системы «научились» классифицировать и идентифицировать «спамовые» сообщения на основе содержимого электронной почты.
Теперь, после обучения этих систем классификации спама, почтовые службы могут использовать их для классификации новых входящих сообщений, чтобы ваш почтовый ящик оставался относительно свободным от нежелательной почты.
Что общего у этих систем
Во всех этих примерах — системах рекомендаций, беспилотных автомобилях и спам-фильтрах — вы заметите наличие потока данных.
Поток данных используется для «обучения» системы машинного обучения. Система машинного обучения «учится» на данных. Затем система выдает некоторый результат, например прогноз, классификацию или рекомендацию.
Хотя все они используют разные методы машинного обучения, все они «учатся» на некотором потоке данных.
По сути, если современные программные системы выполняют какой-либо тип прогнозирования или классификации, есть большая вероятность, что они используют машинное обучение.
Итак, теперь, когда мы рассмотрели несколько примеров машинного обучения, чтобы вы могли увидеть, как оно используется сегодня, давайте посмотрим, как машинное обучение работает на высоком уровне.
Как работает машинное обучение
Существует множество различных типов инструментов машинного обучения, которые имеют разные преимущества и разные области применения.
Несмотря на то, что одна система отличается от другой, есть некоторые общие черты в том, как создаются эти системы машинного обучения.
В таком случае мы можем изучить, как работает процесс построения модели машинного обучения на высоком уровне. Это даст вам приблизительное представление о том, что на самом деле происходит, когда мы используем машинное обучение для набора данных.
По сути, когда мы строим модель машинного обучения, у нас есть набор данных, называемый обучающим набором данных .
Затем мы используем алгоритм для извлечения некоторой информации из этого набора данных. Алгоритм машинного обучения «учится» на обучающих данных.
Как только этот процесс будет завершен, мы можем развернуть модель как систему, которая будет принимать новые данные и будет производить некоторый вывод, когда увидит новые данные. Вообще говоря, этот вывод часто является предсказанием или классификацией того или иного типа.
Но подробности о том, как мы создаем, выбираем и развертываем модель, конечно, немного сложнее.
Давайте быстро рассмотрим процесс создания моделей машинного обучения.
Процесс построения модели
По большей части процесс построения модели представляет собой пошаговый процесс, который проходит по одному и тому же общему пути для каждого проекта.
Конечно, всегда есть небольшие отличия от одного проекта к другому, но на высоком уровне есть несколько типичных шагов при построении системы машинного обучения.
На этом изображении показан процесс построения модели. Это немного упрощает задачу, но дает вам приблизительное представление о том, что происходит, когда вы создаете систему машинного обучения.
Уточнение целей
Как правило, вы начинаете с уточнения целей системы машинного обучения. В бизнес-среде это часто предполагает общение с членами команды и деловыми партнерами для выработки системных требований и результатов.
Получение и очистка данных
Затем вы получаете данные и очищаете данные. Если у вас уже есть опыт работы с наукой о данных, вы, вероятно, слышали, что «обработка данных — это 80% работы» в науке о данных. Это немного сложнее, но это правда, что подготовка и исследование данных — большая часть задачи при создании новой модели машинного обучения.
Это немного сложнее, но это правда, что подготовка и исследование данных — большая часть задачи при создании новой модели машинного обучения.
Построить модели
Затем вы построите несколько моделей. Обратите внимание, что я сказал модель s во множественном числе. Почти во всех случаях вам нужно построить несколько разных моделей. Иногда это означает создание очень похожих моделей, но с небольшими отличиями, которые изменяют или модифицируют производительность. Но это также может означать использование нескольких различных методов машинного обучения для создания различных типов систем машинного обучения. Например, для проекта вы можете построить модель дерева решений, метод опорных векторов и модель логистической регрессии, просто чтобы увидеть, как работает каждый тип модели.
Оцените модели и выберите
И, наконец, когда вы построили несколько моделей, вам необходимо их оценить, выбрать «лучшую» модель в соответствии с требованиями вашего проекта. Выбрав одну из моделей, вы завершаете ее, а затем развертываете модель.
Выбрав одну из моделей, вы завершаете ее, а затем развертываете модель.
Обратите также внимание на стрелки назад, которые иногда перемещают назад к предыдущему шагу в процессе. Это важно. Построение модели машинного обучения является очень итеративным процессом, и иногда вам нужно вернуться назад и повторить предыдущий шаг процесса.
Например, вы можете начать создавать свои модели и понять, что вам нужно больше данных или другие данные. В этом случае вам нужно будет вернуться назад, получить новые данные, очистить их, а затем снова начать выполнять этапы процесса построения модели.
Очевидно, что процесс становится намного сложнее, когда вы действительно начинаете выполнять работу. Есть много мелких деталей, которые я опускаю ради простоты, ясности и краткости.
Но это должно дать вам общее представление о том, как работает процесс построения модели в машинном обучении.
Различные методы машинного обучения
Как я упоминал ранее, существует множество различных методов машинного обучения.
И когда мы создаем систему машинного обучения, мы часто пробуем много разных методов, а затем оцениваем разные модели и сравниваем их друг с другом.
Причина, по которой мы это делаем, заключается в том, что существует множество различных алгоритмов, которые могут работать с наборами данных для получения полезных результатов.
Эти разные алгоритмы — эти разные методы машинного обучения — имеют сильные и слабые стороны.
Некоторые из них работают лучше всего, когда у вас есть небольшие наборы данных.
Другие работают сравнительно лучше, когда у вас есть небольшие наборы данных.
Некоторые лучше работают с высокоструктурированными данными …
Другие работают относительно лучше, когда вы вводите неструктурированные данные.
И так далее…
Существуют десятки (даже сотни) различных методов машинного обучения, в зависимости от того, как вы хотите их классифицировать.
Например, некоторые из распространенных методов машинного обучения:
- линейная регрессия
- логистическая регрессия
- деревья решений
- случайные леса
- бустинг-деревья
- машины опорных векторов почти всех этих инструментов.

Всякий раз, когда вы создаете систему машинного обучения, у вас будут буквально десятки возможных методов и множество способов настройки или оптимизации каждого метода.
Кроме того, выбор правильной техники для решения конкретной задачи — это и искусство, и наука. Есть несколько общих практических правил выбора правильной техники, но здесь также задействовано немного «искусства» в том смысле, что для этого требуются опыт и интуиция, приобретенные за месяцы и годы практики.
Есть чему поучиться
Эта статья должна была дать вам краткий обзор того, что такое машинное обучение и как оно работает.
Но есть еще чему поучиться.
Нам все еще нужно охватить такие темы, как:
- регрессия и классификация
- обучение с учителем и обучение без учителя
- проблема смещения/дисперсии
- проблема переобучения
… и многое другое.
Оставьте свои вопросы в разделе комментариев
Если у вас есть конкретные вопросы о машинном обучении, которые я не затронул в этой статье, оставьте свой вопрос в разделе комментариев внизу страницы.
