
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||






MC216A Hager Двухполюсный автомат 16 А цена в Киеве, Харькове, Днепропетровске, Донецке, Львове (Украина)
Автомат двухполюсный 16 А MC216A Hager с уставкой C позволяет коммутировать одновременно фазный и нулевой проводник.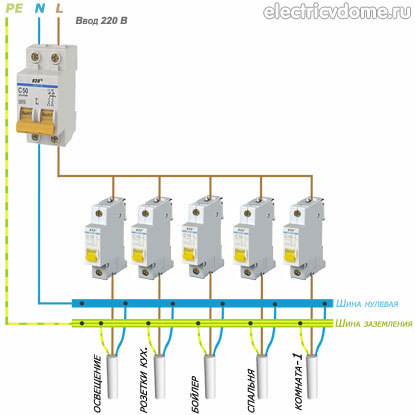 Разрыв фазы и нуля рекомендуют выполнять европейские стандарты в области электротехники для большей надежности и безопасности. Украинские стандарты не предписывают разрывать фазу и ноль, достаточно только фазу. Защитный двухполюсный автоматический выключатель 16 А артикул MC216A Hager защищает линии электропитания от перегрузок и токов короткого замыкания.
Разрыв фазы и нуля рекомендуют выполнять европейские стандарты в области электротехники для большей надежности и безопасности. Украинские стандарты не предписывают разрывать фазу и ноль, достаточно только фазу. Защитный двухполюсный автоматический выключатель 16 А артикул MC216A Hager защищает линии электропитания от перегрузок и токов короткого замыкания.
Двухполюсные автоматические выключатели широко применяются для коммутации сетей постоянного тока. Они позволяют одновременно разрывать оба полюса — «+» и «-«. Напряжение постоянного тока до 125 В. Выпуск автоматов Hager налажен во французском городе Оберней с соблюдением европейских электротехнических стандартов: IEC 898, EN 60 898, DIN VDE0641 часть 11/8.92. Официальный сайт производителя.
Серия оборудования: автоматические выключатели на ток до 63А
Номинальное напряжение сети: 230 В ~, до 125 В = (при последовательном включении двух полюсов)
Номинальный ток: 16 А
Отключающая характеристика (уставка): С
Количество занимаемых модулей на дин-рейке (17,5мм): 2
Сечение присоединяемого проводника: до 25 мм кв
Возможно подключение дополнительных принадлежностей и аксессуаров (независимые расцепители и пр. )
)
Класс защиты IP20
Артикул: MC216A
Производитель: Hager (Хагер, Германия)
Кривая срабатывания С двухполюсного автомата 16 А Hager:
Описание точек графика при работе автомата на переменном токе 50 Гц Точка 1: срабатывание по тепловой уставке от 1,13 Iном Описание точек графика при работе на постоянном токе Точка 1: срабатывание по тепловой уставке от 1,13 Iном |
Влияние температуры окружающей среды на тепловое срабатывание автоматического выключателя Hager:
Допустимая токовая нагрузка на автоматические выключатели Hager, установленные в электрическом щите в один ряд друг за другом, вычисляется путем умножения номинального тока автомата на поправочный коэффициент из таблицы:
Внутренности автоматического выключателя Hager:
Количество полюсов (фаз)
2 полюса (1 фаза + ноль)
Количество модулей
2 модуля
Смешанная точность | TensorFlow Core
Обзор
Смешанная точность — это использование 16-битных и 32-битных типов с плавающей запятой в модели во время обучения, чтобы ускорить ее работу и использовать меньше памяти. Сохраняя определенные части модели в 32-битных типах для числовой стабильности, модель будет иметь меньшее время шага и одинаково хорошо обучаться с точки зрения показателей оценки, таких как точность. В этом руководстве описывается, как использовать API смешанной точности Keras для ускорения ваших моделей. Использование этого API может повысить производительность более чем в 3 раза на современных GPU и на 60% на TPU.
Сохраняя определенные части модели в 32-битных типах для числовой стабильности, модель будет иметь меньшее время шага и одинаково хорошо обучаться с точки зрения показателей оценки, таких как точность. В этом руководстве описывается, как использовать API смешанной точности Keras для ускорения ваших моделей. Использование этого API может повысить производительность более чем в 3 раза на современных GPU и на 60% на TPU.
Сегодня большинство моделей используют dtype float32, занимающий 32 бита памяти. Однако есть два типа d более низкой точности, float16 и bfloat16, каждый из которых вместо этого занимает 16 бит памяти. Современные ускорители могут быстрее выполнять операции в 16-битных dtypes, поскольку они имеют специализированное оборудование для выполнения 16-битных вычислений, а 16-битные dtypes можно быстрее считывать из памяти.
Графические процессоры NVIDIA могут выполнять операции в float16 быстрее, чем в float32, а TPU могут выполнять операции в bfloat16 быстрее, чем в float32. Таким образом, эти dtypes с более низкой точностью следует использовать, когда это возможно, на этих устройствах. Тем не менее, переменные и несколько вычислений все еще должны быть в float32 по числовым причинам, чтобы модель обучалась с тем же качеством. API смешанной точности Keras позволяет использовать сочетание float16 или bfloat16 с float32, чтобы получить преимущества производительности от float16/bfloat16 и преимущества числовой стабильности от float32.
Таким образом, эти dtypes с более низкой точностью следует использовать, когда это возможно, на этих устройствах. Тем не менее, переменные и несколько вычислений все еще должны быть в float32 по числовым причинам, чтобы модель обучалась с тем же качеством. API смешанной точности Keras позволяет использовать сочетание float16 или bfloat16 с float32, чтобы получить преимущества производительности от float16/bfloat16 и преимущества числовой стабильности от float32.
Настройка
импортировать тензорный поток как tf из тензорного потока импортировать керас из слоев импорта tensorflow.keras из tensorflow.keras импортировать смешанную_точность
2022-12-14 03:56:07.992471: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Не удалось загрузить динамическую библиотеку «libnvinfer.so.7»; ошибка & двоеточие; libnvinfer.so.7: не удается открыть общий объектный файл: Данный файл или каталог отсутствует 2022-12-14 03:56:07.992568: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Не удалось загрузить динамическую библиотеку «libnvinfer_plugin.so.7»; ошибка & двоеточие; libnvinfer_plugin.so.7: не удается открыть общий объектный файл: Данный файл или каталог отсутствует 2022-12-14 03:56:07,992577&двоеточие; W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] Предупреждение TF-TRT: Не удается открыть некоторые библиотеки TensorRT. Если вы хотите использовать графический процессор Nvidia с TensorRT, убедитесь, что отсутствующие библиотеки, упомянутые выше, установлены правильно.
Поддерживаемое оборудование
Хотя смешанная точность будет работать на большинстве аппаратных средств, она ускорит модели только на новейших графических процессорах NVIDIA и облачных TPU. Графические процессоры NVIDIA поддерживают сочетание float16 и float32, а TPU — сочетание bfloat16 и float32.
Среди графических процессоров NVIDIA те, у которых вычислительная мощность 7.0 или выше, получат наибольший выигрыш в производительности от смешанной точности, поскольку они имеют специальные аппаратные блоки, называемые тензорными ядрами, для ускорения умножения и свертки матриц с плавающей запятой16. Старые графические процессоры не дают преимущества в математической производительности при использовании смешанной точности, однако экономия памяти и пропускной способности может обеспечить некоторое ускорение. Вы можете посмотреть вычислительные возможности вашего графического процессора на веб-странице графического процессора NVIDIA CUDA. Примеры графических процессоров, которые больше всего выиграют от смешанной точности, включают графические процессоры RTX, V100 и A100.
Примеры графических процессоров, которые больше всего выиграют от смешанной точности, включают графические процессоры RTX, V100 и A100.
Вы можете проверить тип вашего графического процессора следующим образом. Команда существует только в том случае, если Драйверы NVIDIA установлены, поэтому в противном случае следующее вызовет ошибку.
nvidia-smi-L
ГП 0: Tesla P100-PCIE-16GB (UUID: GPU-4085a382-7ba9-6217-eec0-69c9d972f8b8) ГП 1: Tesla P100-PCIE-16GB (UUID: GPU-74a03c5f-68af-a74f-7fd8-9d41f665cb2c) ГП 2: Tesla P100-PCIE-16GB (UUID: GPU-c821432d-533b-aa21-8a59-6c213fe0e44d) ГП 3: Tesla P100-PCIE-16GB (UUID: GPU-50cba888-7483-234a-525f-5feaa2f49edd)
Все облачные TPU поддерживают bfloat16.
Даже на ЦП и старых графических процессорах, где не ожидается ускорения, API-интерфейсы смешанной точности можно использовать для модульного тестирования, отладки или просто для опробования API. Однако на процессорах смешанная точность будет работать значительно медленнее.
Установка политики dtype
Чтобы использовать смешанную точность в Keras, вам необходимо создать tf.keras.mixed_precision.Policy , обычно называемую политикой dtype . Политики Dtype определяют, в каких слоях dtypes будут работать. В этом руководстве вы создадите политику из строки 'mixed_float16' и установите ее в качестве глобальной политики. Это приведет к тому, что впоследствии созданные слои будут использовать смешанную точность со смесью float16 и float32.
политика = смешанная_точность.Политика('смешанный_поплавок16')
смешанная_прецизионность. set_global_policy(политика)
set_global_policy(политика)
ПРЕДУПРЕЖДЕНИЕ:tensorflow:Проверка совместимости со смешанной точностью (mixed_float16): ПРЕДУПРЕЖДЕНИЕ Ваши графические процессоры могут работать медленно с политикой dtype mix_float16, потому что они не имеют вычислительных возможностей по крайней мере 7.0. Ваши графические процессоры: Tesla P100-PCIE-16GB, вычислительная мощность 6.0 (x4) См. https://developer.nvidia.com/cuda-gpus для получения списка графических процессоров и их вычислительных возможностей. Если вы будете использовать совместимые графические процессоры, не подключенные к этому хосту, например. запустив модель с несколькими рабочими, вы можете игнорировать это предупреждение. Это сообщение будет зарегистрировано только один раз
Для краткости вы можете напрямую передать строку в set_global_policy , что обычно и делается на практике.
# Эквивалентно двум строкам выше смешанная_прецизионность.set_global_policy('mixed_float16')
Политика определяет два важных аспекта слоя: тип d, в котором выполняются вычисления слоя, и тип d переменных слоя. Выше вы создали политику Mixed_Float16 (т. е. Mixed_precision.Policy , созданную путем передачи строки 'mixed_float16' в его конструктор). С этой политикой слои используют вычисления float16 и переменные float32. Вычисления выполняются в формате float16 для повышения производительности, но переменные должны храниться в формате float32 для стабильности числовых значений. Вы можете напрямую запросить эти свойства политики.
print('Тип вычисления: %s' % policy.compute_dtype)
print('Тип переменной: %s' % policy.variable_dtype)
Вычислить dtype: поплавок16 Переменная dtype: поплавок32
Как упоминалось ранее, Mixed_float16 значительно улучшит производительность графических процессоров NVIDIA с вычислительной мощностью не ниже 7. 0. Политика будет работать на других GPU и CPU, но может не повысить производительность. Вместо этого для TPU следует использовать политику
0. Политика будет работать на других GPU и CPU, но может не повысить производительность. Вместо этого для TPU следует использовать политику mixed_bfloat16 .
Построение модели
Теперь приступим к построению простой модели. Очень маленькие игрушечные модели обычно не выигрывают от смешанной точности, поскольку накладные расходы среды выполнения TensorFlow обычно доминируют над временем выполнения, что делает любое улучшение производительности на графическом процессоре незначительным. Поэтому построим два больших Плотные слоев по 4096 единиц в каждом, если используется графический процессор.
входных данных = keras.Input (форма = (784,), имя = 'цифры')
если tf.config.list_physical_devices('GPU'):
print('Модель будет работать с 4096 юнитами на графическом процессоре')
количество_единиц = 4096
еще:
# Используйте меньше блоков на процессорах, чтобы модель завершилась за разумное время
print('Модель будет работать с 64 юнитами на процессоре')
количество_единиц = 64
плотный1 = слои. Плотный (количество_единиц, активация = 'relu', имя = 'плотный_1')
х = плотно1 (входы)
плотный2 = слои. Плотный (количество_единиц, активация = 'relu', имя = 'плотный_2')
х = плотно2 (х)
Плотный (количество_единиц, активация = 'relu', имя = 'плотный_1')
х = плотно1 (входы)
плотный2 = слои. Плотный (количество_единиц, активация = 'relu', имя = 'плотный_2')
х = плотно2 (х)
Модель будет работать с 4096 единицами на графическом процессоре.
Каждый уровень имеет политику и по умолчанию использует глобальную политику. Таким образом, каждый из слоев Dense имеет политику mixed_float16 , поскольку ранее вы установили глобальную политику на mixed_float16 . Это заставит плотные слои выполнять вычисления с плавающей запятой 16 и иметь переменные с плавающей точкой 32. Они приводят свои входные данные к типу с плавающей запятой16, чтобы выполнять вычисления с плавающей точкой16, что в результате приводит к тому, что их выходные данные имеют значение с плавающей запятой16. Их переменные имеют тип float32 и будут преобразованы в float16 при вызове слоев, чтобы избежать ошибок из-за несоответствия dtype.
печать (dense1.dtype_policy)
print('x.dtype: %s' % x.dtype.name)
# 'kernel' - это переменная плотности 1
print('dense1.kernel.dtype: %s' % плотности1.kernel.dtype.name)
<Политика "mixed_float16"> x.dtype: поплавок16 плотный1.kernel.dtype: поплавок32
Затем создайте выходные прогнозы. Обычно вы можете создавать выходные прогнозы следующим образом, но это не всегда численно стабильно с float16.
# НЕПРАВИЛЬНО: вывод softmax и модели будет float16, а должен быть float32
выходы = слои. Плотность (10, активация = 'softmax', имя = 'предсказания') (x)
print('Вывод dtype: %s' % outputs.dtype.name)
Выводит dtype: поплавок16
Активация softmax в конце модели должна быть float32. Поскольку политика dtype — mixed_float16 , активация softmax обычно будет иметь dtype вычислений float16 и тензоры float16 вывода.
Это можно исправить, разделив слои Dense и softmax и передав dtype='float32' слою softmax:
# ПРАВИЛЬНО: softmax и выходные данные модели являются float32
x = слои.Dense(10, name='dense_logits')(x)
выходы = слои.Активация('softmax', dtype='float32', name='predictions')(x)
print('Вывод dtype: %s' % outputs.dtype.name)
Выводит dtype: поплавок32
Передача dtype='float32' в конструктор слоя softmax переопределяет политику dtype слоя на политику float32 , которая выполняет вычисления и хранит переменные в float32. Эквивалентно, вместо этого вы могли бы передать dtype=mixed_precision.Policy('float32') ; слои всегда преобразовывают аргумент dtype в политику. Поскольку уровень Activation не имеет переменных, переменная dtype политики игнорируется, но вычисление dtype политики, равное float32, приводит к тому, что softmax и выходные данные модели будут float32.
Добавление softmax float16 в середине модели — это нормально, но softmax в конце модели должен быть в float32. Причина в том, что если промежуточный тензор, идущий от softmax к убытку, равен float16 или bfloat16, могут возникнуть числовые проблемы.
Вы можете изменить dtype любого слоя на float32, передав dtype='float32' , если вы считаете, что он не будет численно стабильным с вычислениями float16. Но обычно это необходимо только на последнем слое модели, так как большинство слоев имеют достаточную точность с смешанный_поплавок16 и смешанный_bпоплавок16 .
Даже если модель не заканчивается на softmax, выходные данные все равно должны быть float32. Хотя для этой конкретной модели это необязательно, выходные данные модели можно привести к типу float32 с помощью следующего:
# Линейная активация является функцией тождества.Так что это просто выводит «выходы» # для плавания32. В данном конкретном случае «выходы» уже имеют значение float32, так что это # не работает. выходы = слои.Активация('linear', dtype='float32')(выходы)
Затем завершите и скомпилируйте модель и сгенерируйте входные данные:
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile (потеря = 'sparse_categorical_crossentropy',
оптимизатор=keras.optimizers.RMSprop(),
метрики=['точность'])
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype('float32') / 255
x_test = x_test.reshape(10000, 784).astype('float32') / 255
В этом примере входные данные преобразуются из int8 в float32. Вы не выполняете приведение к float16, поскольку деление на 255 выполняется процессором, который выполняет операции с плавающей запятой медленнее, чем операции с плавающей запятой32. В этом случае разница в производительности незначительна, но в целом вы должны запускать математику обработки ввода в float32, если она выполняется на ЦП. Первый уровень модели будет приводить входные данные к типу float16, поскольку каждый слой преобразует входные данные с плавающей запятой к своему вычислительному типу.
Первый уровень модели будет приводить входные данные к типу float16, поскольку каждый слой преобразует входные данные с плавающей запятой к своему вычислительному типу.
Получены начальные веса модели. Это позволит снова тренироваться с нуля, загружая веса.
начальные_веса = модель.get_weights()
Обучение модели с помощью Model.fit
Далее, обучение модели:
history = model.fit(x_train, y_train,
размер партии = 8192,
эпохи=5,
validation_split=0,2)
test_scores = model.evaluate (x_test, y_test, подробный = 2)
print('Проигрыш в тесте:', test_scores[0])
print('Точность теста:', test_scores[1])
Эпоха 1/5 6/6 [==============================] - 2 с 202 мс/шаг - потеря&двоеточие; 2,6197 - точность&двоеточие; 0,3875 - val_loss: 0,7951 - val_accuracy: 0,8290 Эпоха 2/5 6/6 [==============================] - 1 с 156 мс/шаг - потеря&двоеточие; 0,9418 - точность&двоеточие; 0.7210 - val_loss: 0.4762 - val_accuracy: 0,8877 Эпоха 3/5 6/6 [==============================] - 1 с 155 мс/шаг - потеря&двоеточие; 0,4998 - точность&двоеточие; 0,8549 - val_loss: 0,7045 - val_accuracy: 0,7447 Эпоха 4/5 6/6 [==============================] - 1 с 156 мс/шаг - потеря&двоеточие; 0,4647 - точность&двоеточие; 0,8544 - val_loss: 0.2608 - val_accuracy: 0,9250 Эпоха 5/5 6/6 [==============================] - 1 с 156 мс/шаг - потеря&двоеточие; 0,3179 - точность&двоеточие; 0.9022 - val_loss: 0,3698 - val_accuracy: 0,8745 313/313 - 1s - потеря&двоеточие; 0,3833 - точность&двоеточие; 0,8649 - 644 мс/эпоха - 2 мс/шаг Потеря теста&двоеточие; 0,38325420022010803 Проверка точности&колон; 0,8648999929428101
Обратите внимание, что модель печатает в журналах время на шаг: например, «25 мс/шаг». Первая эпоха может быть медленнее, так как TensorFlow тратит некоторое время на оптимизацию модели, но впоследствии время на шаг должно стабилизироваться.
Если вы запускаете это руководство в Colab, вы можете сравнить производительность смешанной точности с float32. Для этого измените политику с mixed_float16 на float32 в разделе «Настройка политики dtype», затем перезапустите все ячейки до этого момента. На графических процессорах с вычислительными возможностями 7.X вы должны увидеть значительное увеличение времени на шаг, что указывает на то, что смешанная точность ускорила модель. Обязательно измените политику обратно на mixed_float16 и повторно запустите ячейки, прежде чем продолжить работу с руководством.
На графических процессорах с вычислительной мощностью не ниже 8.0 (графические процессоры Ampere и выше) вы, скорее всего, не увидите повышения производительности игрушечной модели в этом руководстве при использовании смешанной точности по сравнению с float32. Это связано с использованием TensorFloat-32, который автоматически использует математику с более низкой точностью в некоторых операциях float32, таких как tf. . TensorFloat-32 дает некоторые преимущества производительности смешанной точности при использовании float32. Тем не менее, в реальных моделях вы по-прежнему будете испытывать значительный прирост производительности от смешанной точности из-за экономии пропускной способности памяти и операций, которые TensorFloat-32 не поддерживает. linalg.matmul
linalg.matmul
При использовании смешанной точности на TPU вы не увидите такого большого прироста производительности по сравнению со смешанной точностью на графических процессорах, особенно на графических процессорах до Ampere. Это связано с тем, что TPU выполняют определенные операции в bfloat16 под капотом даже с политикой dtype по умолчанию float32. Это похоже на то, как графические процессоры Ampere по умолчанию используют TensorFloat-32. По сравнению с графическими процессорами Ampere, TPU обычно демонстрируют меньший прирост производительности при смешанной точности на реальных моделях.
Для многих реальных моделей смешанная точность также позволяет удвоить размер пакета без нехватки памяти, поскольку тензоры float16 занимают половину памяти. {-8}\) будут уменьшаться до нуля. float32 и bfloat16 имеют гораздо более широкий динамический диапазон, так что переполнение и потеря значимости не являются проблемой.
{-8}\) будут уменьшаться до нуля. float32 и bfloat16 имеют гораздо более широкий динамический диапазон, так что переполнение и потеря значимости не являются проблемой.
Например:
x = tf.constant(256, dtype='float16') (x ** 2).numpy() # Переполнение
инф
x = tf.constant(1e-5, dtype='float16') (x ** 2).numpy() # Потеря памяти
0,0
На практике переполнение с float16 происходит редко. Кроме того, во время прямого прохода также редко возникает недолив. Однако при обратном проходе градиенты могут опускаться до нуля. Масштабирование убытков — это метод предотвращения этого недорасхода.
Обзор масштабирования потерь
Основная концепция масштабирования убытков проста: просто умножьте убыток на некоторое большое число, скажем, \(1024\), и вы получите значение шкалы убытков . Это также приведет к масштабированию градиентов на \(1024\), что значительно уменьшит вероятность потери значимости. Как только окончательные градиенты будут вычислены, разделите их на \(1024\), чтобы вернуть их к правильным значениям.
Это также приведет к масштабированию градиентов на \(1024\), что значительно уменьшит вероятность потери значимости. Как только окончательные градиенты будут вычислены, разделите их на \(1024\), чтобы вернуть их к правильным значениям.
Псевдокод для этого процесса:
loss_scale = 1024 потеря = модель (входы) убыток *= масштаб_убытка # Предположим, что `градусы` равны float32. Вы не хотите делить градиенты float16. grads = вычислить_градиент (потери, model.trainable_variables) град /= loss_scale
Выбор шкалы потерь может быть сложным. Если шкала потерь слишком мала, градиенты все равно могут опускаться до нуля. Если слишком высокое, возникает обратная проблема: градиенты могут выйти за пределы бесконечности.
Чтобы решить эту проблему, TensorFlow динамически определяет масштаб потерь, поэтому вам не нужно выбирать его вручную. Если вы используете tf.keras.Model.fit , масштабирование потерь выполняется за вас, поэтому вам не нужно выполнять дополнительную работу. Если вы используете пользовательский цикл обучения, вы должны явно использовать специальную оболочку оптимизатора
Если вы используете пользовательский цикл обучения, вы должны явно использовать специальную оболочку оптимизатора tf.keras.mixed_precision.LossScaleOptimizer для использования масштабирования потерь. Это описано в следующем разделе.
Обучение модели с помощью пользовательского цикла обучения
До сих пор вы обучали модель Keras со смешанной точностью, используя tf.keras.Model.fit . Далее вы будете использовать смешанную точность с пользовательским циклом обучения. Если вы еще не знаете, что такое настраиваемый цикл обучения, сначала прочтите Руководство по настраиваемому обучению.
Запуск пользовательского цикла обучения со смешанной точностью требует двух изменений по сравнению с запуском в float32:
- Построить модель со смешанной точностью (вы это уже делали)
- Явно использовать масштабирование убытков, если используется
mixed_float16.
Для шага (2) вы будете использовать класс tf.keras.mixed_precision.LossScaleOptimizer , который обертывает оптимизатор и применяет масштабирование потерь. По умолчанию он динамически определяет масштаб потерь, поэтому вам не нужно его выбирать. Создайте LossScaleOptimizer следующим образом.
оптимизатор = keras.optimizers.RMSprop() оптимизатор = смешанная_точность.LossScaleOptimizer(оптимизатор)
При желании можно выбрать явную шкалу потерь или иным образом настроить поведение масштабирования потерь, но настоятельно рекомендуется сохранить поведение масштабирования потерь по умолчанию, так как было обнаружено, что оно хорошо работает на всех известных моделях. См. документацию tf.keras.mixed_precision.LossScaleOptimizer , если вы хотите настроить поведение масштабирования потерь.
Затем определите объект потерь и tf. s: data.Dataset
data.Dataset
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
train_dataset = (tf.data.Dataset.from_tensor_slices((x_train, y_train))
.перетасовать(10000).пакет(8192))
test_dataset = tf.data.Dataset.from_tensor_slices((x_test, y_test)).batch(8192)
Затем определите функцию шага обучения. Вы будете использовать два новых метода оптимизатора шкалы потерь для масштабирования потерь и немасштабирования градиентов:
-
get_scaled_loss(loss): умножает потери на шкалу потерь -
get_unscaled_gradients(gradients): принимает список масштабированных градиентов в качестве входных данных и делит каждый из них на шкалу потерь, чтобы не масштабировать их
Эти функции необходимо использовать для предотвращения недополнения в градиентах. LossScaleOptimizer.apply_gradients затем применит градиенты, если ни один из них не имеет Inf s или NaN s. Он также обновит шкалу потерь, уменьшив ее вдвое, если градиенты имели
Он также обновит шкалу потерь, уменьшив ее вдвое, если градиенты имели Inf с или NaN с, и потенциально увеличив ее в противном случае.
@tf.функция
def train_step (x, y):
с tf.GradientTape() в качестве ленты:
прогнозы = модель (х)
потеря = объект_потери (у, прогнозы)
scaled_loss = оптимизатор.get_scaled_loss(потеря)
масштабируемые_градиенты = лента.градиент (масштабированные_потери, модель.обучаемые_переменные)
градиенты = оптимизатор.get_unscaled_gradients(scaled_gradients)
оптимизатор.apply_gradients(zip(градиенты, model.trainable_variables))
обратные потери
LossScaleOptimizer , скорее всего, пропустит первые несколько шагов в начале обучения. Шкала потерь начинается высоко, так что можно быстро определить оптимальную шкалу потерь. Через несколько шагов шкала потерь стабилизируется, и очень немногие шаги будут пропущены. Этот процесс происходит автоматически и не влияет на качество обучения.
Этот процесс происходит автоматически и не влияет на качество обучения.
Теперь определите этап проверки:
@tf.function определение test_step(x): модель возврата (x, обучение = False)
Загрузите начальные веса модели, чтобы вы могли переобучиться с нуля:
модель.set_weights(initial_weights)
Наконец, запустите пользовательский цикл обучения:
для эпохи в диапазоне (5):
epoch_loss_avg = tf.keras.metrics.Mean()
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(
имя = 'test_accuracy')
для x, y в train_dataset:
потеря = шаг_поезда (х, у)
epoch_loss_avg (потеря)
для x, y в test_dataset:
прогнозы = test_step (x)
test_accuracy.update_state(y, прогнозы)
print('Эпоха {}: потеря={}, точность теста={}'.format(эпоха, epoch_loss_avg.result(), test_accuracy.result()))
Эпоха 0: потеря = 2,1030306816101074, точность теста = 0,5697000026702881 Эпоха 1: потеря = 0,72940903383, точность теста = 0,7651000022888184 Эпоха 2: потеря = 0,46808382868766785, точность теста = 0,9204000234603882 Эпоха 3: потеря = 0,3774358034133911, точность теста = 0,8847000002861023 Эпоха 4: потеря = 0,2915167212486267, точность теста = 0,9106000065803528
Советы по повышению производительности графического процессора
Вот несколько советов по повышению производительности при использовании смешанной точности на графических процессорах.
Увеличение размера партии
Если это не повлияет на качество модели, попробуйте запустить удвоение размера партии при использовании смешанной точности. Поскольку тензоры float16 используют половину памяти, это часто позволяет вам удвоить размер пакета без нехватки памяти. Увеличение размера пакета обычно увеличивает пропускную способность обучения, то есть количество обучающих элементов в секунду, на которых может работать ваша модель.
Обеспечение использования тензорных ядер графического процессора
Как упоминалось ранее, современные графические процессоры NVIDIA используют специальный аппаратный блок, называемый тензорными ядрами, который может очень быстро умножать матрицы с плавающей запятой16. Однако тензорные ядра требуют, чтобы определенные размеры тензоров были кратны 8. В приведенных ниже примерах аргумент выделен жирным шрифтом тогда и только тогда, когда для использования тензорных ядер он должен быть кратен 8.
- tf.keras.layers.Dense( единиц=64 )
- tf.keras.layers.Conv2d ( фильтров = 48 , размер ядра = 7, шаг = 3)
- И аналогично для других сверточных слоев, таких как tf.keras.layers.Conv3d
- tf.keras.layers.LSTM( единиц=64 )
- И аналогично для других RNN, таких как tf.keras.layers.GRU
- tf.keras.Model.fit(эпохи=2, batch_size=128 )
По возможности старайтесь использовать тензорные ядра. Если вы хотите узнать больше, руководство NVIDIA по производительности глубокого обучения описывает точные требования для использования тензорных ядер, а также другую информацию о производительности, связанную с тензорными ядрами.
XLA
XLA — это компилятор, который может дополнительно повысить производительность смешанной точности, а также в меньшей степени производительность float32. Подробную информацию см. в руководстве XLA.
в руководстве XLA.
Советы по повышению производительности Cloud TPU
Как и в случае с GPU, при использовании Cloud TPU следует попытаться удвоить размер пакета, поскольку тензоры bfloat16 используют половину памяти. Удвоение размера пакета может увеличить производительность обучения.
TPU не требуют какой-либо другой настройки смешанной точности для достижения оптимальной производительности. Они уже требуют использования XLA. TPU выигрывают от того, что некоторые размеры кратны \(128\), но это в равной степени относится к типу float32, как и к смешанной точности. Ознакомьтесь с руководством по производительности Cloud TPU, чтобы узнать общие советы по производительности TPU, которые применимы как к тензорам со смешанной точностью, так и к тензорам с плавающей запятой.
Сводка
- Если вы используете TPU или GPU NVIDIA с вычислительной мощностью не ниже 7.0, вам следует использовать смешанную точность, так как это повысит производительность до 3 раз.

Вы можете использовать смешанную точность со следующими строками:
# На TPU вместо этого используйте 'mixed_bfloat16' смешанная_прецизионность.set_global_policy('mixed_float16')Если ваша модель заканчивается на softmax, убедитесь, что это float32. И независимо от того, чем заканчивается ваша модель, убедитесь, что вывод имеет тип float32.
Если вы используете пользовательский цикл обучения с
mixed_float16, в дополнение к вышеуказанным строкам, вам необходимо обернуть свой оптимизаторtf.keras.mixed_precision.LossScaleOptimizer. Затем вызовитеoptimizer.get_scaled_loss, чтобы масштабировать потери, иoptimizer.get_unscaled_gradients, чтобы немасштабировать градиенты.Удвойте размер обучающей партии, если это не снижает точность оценки
На графических процессорах убедитесь, что размерность большинства тензоров кратна \(8\), чтобы максимизировать производительность
В качестве примера смешанной точности с использованием API tf. проверьте функции и классы, связанные с эффективностью обучения. Ознакомьтесь с официальными моделями, такими как Transformer, для получения подробной информации. keras.mixed_precision
keras.mixed_precision
Что такое автоматический выключатель и как он работает?
На этой странице
Проблема
Темная и ненастная ночь. Вы включаете свет в холле, включаете кофеварку и включаете переносной электрический обогреватель. Вы начинаете чувствовать себя комфортно, когда слышите слабый, но зловещий щелчок — и все становится черным. Это не кошачий грабитель или полтергейст, играющий с вашей электрической системой. Это перегруженная цепь, защищенная сработавшим автоматическим выключателем. Какой-то жуткий и загадочный, а? Нет, если вы знаете несколько простых вещей.
Семейный мастер на все руки
Рисунок A: Правильно функционирующая цепь на 15 А
В этой цепи есть провода и автоматический выключатель, который может легко выдерживать силу тока, необходимую для устройств
.
Что такое цепь?
Когда электричество поступает в ваш дом, оно поступает в блок выключателя (или блок предохранителей в старых домах), где делится на несколько цепей. Каждая цепь защищена выключателем или предохранителем. Спальни, гостиные и семейные комнаты, где обычно используются только светильники, будильники и другие мелкие электроприборы, обычно подключаются к 15-амперным цепям. Кухни, прачечные, ванные комнаты и столовые — места, где вы, скорее всего, будете использовать тостеры, утюги, фены и другие мощные устройства — обычно обслуживаются более мощными 20-амперными цепями. Крупные бытовые приборы, такие как электрические водонагреватели на 5000 Вт и электрические плиты на 10 000 Вт, потребляют так много электроэнергии, что используют собственную выделенную цепь на 30–50 ампер (см.0010, рис. D в разделе «Дополнительная информация» ниже), защищены большими «двухполюсными» автоматическими выключателями.
Что такое перегрузка цепи?
Автоматический выключатель, провод и даже изоляция провода предназначены для работы как система, и эта система имеет ограничения. Попробуйте пропустить через цепь больший ток, чем она рассчитана, и все начнет происходить ( рис. B ). Провода нагреваются под бременем пропускания избыточного тока. Когда это происходит, изоляция вокруг провода может разрушиться или даже расплавиться. Когда изоляция плавится, ток больше не ограничивается проводом. Вот когда начинаются пожары. К счастью, автоматический выключатель обнаруживает избыточный ток и «срабатывает», чтобы остановить поток энергии до того, как произойдет повреждение.
Попробуйте пропустить через цепь больший ток, чем она рассчитана, и все начнет происходить ( рис. B ). Провода нагреваются под бременем пропускания избыточного тока. Когда это происходит, изоляция вокруг провода может разрушиться или даже расплавиться. Когда изоляция плавится, ток больше не ограничивается проводом. Вот когда начинаются пожары. К счастью, автоматический выключатель обнаруживает избыточный ток и «срабатывает», чтобы остановить поток энергии до того, как произойдет повреждение.
В ту ночь, когда в вашем доме погас свет, вы были в порядке, только свет и кофеварка работали. Настоящая беда началась, когда ты подключил этот проклятый обогреватель.
Семейный мастер на все руки
Рисунок B: Цепь с перегрузкой
В этой цепи слишком много энергоемких устройств, и она пытается выдерживать большую силу тока, чем рассчитана. Вещи начинают нагреваться. К счастью, автоматический выключатель это чувствует, срабатывает и «разрывает» цепь.
Как рассчитать амперы, вольты и ватты
Чтобы начать решать задачу, нам нужно знать одну простую формулу «правила большого пальца». Эта формула поможет нам определить, перегружают ли ее все электрические элементы в конкретной цепи. Эта формула также помогает определить некоторые повседневные термины и то, как они соотносятся друг с другом. В конце концов, лампочки и обогреватели имеют маркировку в ваттах; инструменты и автоматические выключатели в амперах; и наша бытовая электрическая система в вольтах: как они все сочетаются друг с другом?
Простая формула ( рис. C ) говорит нам, как: Ватт, деленный на напряжение, равен амперам. Другие показанные уравнения — это просто другие способы сказать то же самое.
Напряжение проще всего можно описать как давление, под которым движется электричество — цепь электронов. Большая часть бытового тока подается при напряжении 120 вольт, хотя ток для крупных электроприборов подается при более высоком напряжении 240 вольт.
Ампер (или ампер) — это мера количества электронов, которое напряжение выталкивает через заданную точку в
одна секунда.
Ватт — единица измерения электрической мощности. Он показывает, сколько электронов было пропущено через электрическое устройство, чтобы заставить его работать. Это то, за что электрическая компания выставляет вам счет.
Семейный мастер на все руки
Рисунок C: Базовая формула
Используйте эти простые уравнения для преобразования различных измерений электроэнергии, чтобы помочь определить такие вещи, как количество розеток на 15-амперном выключателе или количество ламп на 15-амперной цепи.
Узнайте о советах по упрощению электропроводки дома здесь.
Почему срабатывают выключатели?
Сила цепи и автоматического выключателя, которые вы отключили, составляет 15 ампер или 1800 ватт (15 ампер x 120 вольт = 1800 ватт). Свет потреблял 360 ватт или жалкие 3 ампера (360 ватт разделить на 120 вольт = 3 ампера) — вполне в пределах мощности вашей 15-амперной системы. 800-ваттная кофеварка (деленная на 120 вольт) потребляла 6,6 ампера, что значительно больше, чем мощность ламп, но их суммарная мощность составляла 9 ампер.Потребляемый ток 0,6 ампера все еще находится в пределах 15-амперной схемы.
800-ваттная кофеварка (деленная на 120 вольт) потребляла 6,6 ампера, что значительно больше, чем мощность ламп, но их суммарная мощность составляла 9 ампер.Потребляемый ток 0,6 ампера все еще находится в пределах 15-амперной схемы.
Но когда вы подключили 1200-ваттный обогреватель, требуемые для него 10 ампер плюс потребление двух других устройств потребовали 19,6 ампер через 15-амперную систему ( рис. B ). Это как питон, проглотивший свинью; система просто не справляется с нагрузкой. Автоматический выключатель терпел это некоторое время. Но когда избыточный ток и возникающее в результате тепло начали деформировать два куска металла внутри выключателя, они начали «нажимать на курок». И когда металлические детали сгибались до определенной точки, спусковой крючок разрывал две контактные точки, прерывая поток электричества и отключая эту цепь. Если в цепи возникает внезапное сильное напряжение, небольшой электромагнит в автоматическом выключателе может также разъединить контактные точки. Если у вас есть предохранители, избыточное тепло плавит провод внутри предохранителя, что, в свою очередь, останавливает поток электричества.
Если у вас есть предохранители, избыточное тепло плавит провод внутри предохранителя, что, в свою очередь, останавливает поток электричества.
Если бы это был 20-амперный выключатель с более толстым проводом № 12, способным выдерживать 2400 ватт, то выключатель не сработал бы. Но как только провод находится в стене, а выключатель в коробке выключателя, вы мало что можете сделать, чтобы модернизировать установленную цепь. Но у вас есть другие варианты.
Сети на 240 В
Для более крупных приборов, таких как электрические водонагреватели, сушилки и плиты, требуется столько энергии, что электричество к ним подается по сетям на 240 В. Все потому, что напряжение в 240-вольтовых цепях «давит» в два раза сильнее. Например, для электрического флюгельгорна мощностью 6000 ватт в цепи 120 вольт потребуется цепь 50 ампер (6000 ватт разделить на 120 вольт = 50 ампер). Для этого потребуются гигантские провода. Но для того же флюгельгорна на 6000 ватт в цепи 240 вольт требуется только цепь на 25 ампер (6000 разделить на 240 = 25), а также меньший провод и автоматический выключатель.
Решение первое — краткосрочное решение
Простое решение — подключить обогреватель к розетке цепи с избыточной мощностью. Вы можете довольно легко определить существующую нагрузку на цепь: выключите автоматический выключатель, затем включите выключатели света и проверьте розетки, чтобы увидеть, какие из них больше не работают. Затем сложите общую ваттную нагрузку устройств в этой цепи. Это часто легче сказать, чем сделать. Иногда цепь с надписью «спальня» подключается к розеткам в прачечной. Или верхние и нижние розетки дуплексной розетки будут на разных цепях. После того, как вы наметите схему и суммируете электрические нагрузки, вы сможете определить, сможете ли вы подключить к цепи больше устройств, не перегружая ее.
При суммировании электрических нагрузок имейте в виду, что провод, рассчитанный на 15 ампер, может нести 15 ампер в течение всего дня. Однако 15-амперные выключатели и предохранители могут постоянно выдерживать только 12 ампер — 80 процентов от их номинала. Непрерывной считается схема, загруженная до предела в течение трех и более часов. Это правило 80 процентов применяется ко всем выключателям и предохранителям. Более подробную информацию о расчете нагрузок см. в разделе Предотвращение электрических перегрузок.
Непрерывной считается схема, загруженная до предела в течение трех и более часов. Это правило 80 процентов применяется ко всем выключателям и предохранителям. Более подробную информацию о расчете нагрузок см. в разделе Предотвращение электрических перегрузок.
Решение второе — долгосрочное исправление
Наилучшее долгосрочное решение — установка новой специальной цепи и выхода для обогревателя. Большинство электриков предложат специальную цепь для любого прибора, который потребляет более половины мощности цепи. На рис. D в разделе «Дополнительная информация» (ниже) показана мощность приборов, которые обычно имеют выделенные цепи. Каждый раз, когда вы устанавливаете большой электроприбор — будь то 120 или 240 вольт — устанавливайте его на отдельной выделенной цепи с проводом нужного размера и автоматическим выключателем.
Как видно из рис. E , 20-амперный выключатель с более толстым проводом № 12 может пропускать больший ток, чем 15-амперная цепь с проводом № 14. Когда вы подключаете или переделываете электропроводку на кухне, в прачечной, ванной или столовой, Национальный электротехнический кодекс требует от вас установки 20-амперных цепей, которые могут пропускать больший ток. Если вы используете много электроинструментов, имеет смысл использовать 20-амперные схемы и для вашего гаража, мастерской и подвала.
Когда вы подключаете или переделываете электропроводку на кухне, в прачечной, ванной или столовой, Национальный электротехнический кодекс требует от вас установки 20-амперных цепей, которые могут пропускать больший ток. Если вы используете много электроинструментов, имеет смысл использовать 20-амперные схемы и для вашего гаража, мастерской и подвала.
Информацию о подключении новой цепи см. в разделе Как подключить новую цепь.
Семейный мастер на все руки
Рисунок E: Сечения проводов
Провод большего размера 12-го калибра может безопасно выдерживать большую силу тока, чем меньший провод 14-го размера, без перегрева.
Узнайте о 8 наиболее распространенных нарушениях электротехнических правил здесь.
Вмешательство запрещено
У домовладельцев, которые кладут «копейку в блок предохранителей», чтобы предотвратить перегорание предохранителей, происходит короткое замыкание мозга. Без предохранителя, который прерывает поток энергии, когда через цепь проходит слишком много ампер, провода перегреваются, изоляция проводов плавится и возникает пожар.