
Провода РКГМ — технические характеристики, описание, расшифровка, ГОСТ
Расшифровка провода РКГМ:
РК — изоляция из резины кремнийорганическойГ — гибкий
М — защитная оплетка из стекловолокна, пропитанная эмалью или теплостойким лаком
Элементы конструкции провода РКГМ:
Токопроводящая жила – медная, многопроволочная класса 5 по ГОСТ 22483.Изоляция – из кремнийорганической резины.
Защитная оплетка – из стекловолокна, пропитанной эмалью или теплостойким лаком.
Область применения провода РКГМ:
Провод предназначен для выводных концов электрических машин и аппаратов на переменное напряжение до 660 и 1140 В частотой соответственно до 400 и 60 Гц.Провод предназначен для работы при напряжении 660В частотой до 400 Гц, при отсутствии воздействия агрессивных сред и масел.
Технические параметры провода РКГМ:
Вид климатического исполнения провода — О2.Класс нагревостойкости — Н.
Длительно допустимая температура эксплуатации провода — от минус 60 до 180°С.

Провод стойкий к воздействию пониженного атмосферного давления до 1,3 кПа (1мм рт.ст.) и повышенного атмосферного давления до 294 кПа (Зкгс/см²), вибраций, механических ударов.
Провод предназначен для эксплуатации при относительной влажности воздуха до 100% при температуре до 35°С.
Монтаж провода без предварительного нагрева должен производиться при температуре не ниже минус 15°С.
Минимальный радиус изгиба при монтаже — не менее 2 диаметра провода.
Провод выдерживает не менее 10 циклов изгибов вокруг цилиндра диаметром, равным двукратному диаметру провода.
Электрическое сопротивление изоляции 1 км провода после пребывания в воде не менее 3 ч при температуре (20+5)°С, не менее:
— номинальным сечением 0,75-2,5мм2 — 250 МОм;
— номинальным сечением 3,0-4,0мм2 — 200 МОм;
— номинальным сечением 5,0-8,0мм2 — 170 МОм;
— номинальным сечением 10,0-16,0мм2 — 150 МОм;
— номинальным сечением 25,0-50,0мм2 — 110 МОм;
— номинальным сечением 70,0-120,0мм2 — 90 МОм.

Срок службы провода — не менее 8 лет.
ГОСТ (ТУ / VDE) провода РКГМ:
- ТУ 16.К80-09-90 (Камкабель; Рыбинсккабель; Липаркабель; Коаксиал; Уралкабель; ХКА)
Провод РКГМ: основные характеристики
Характеристики проводов РКГМ
Провод термостойкий РКГМ достаточно широко применяется как в промышленности, так и в быту. Его уникальные свойства позволяют применять его в жарких и особо жарких помещениях, в помещениях с воздействием агрессивных химических сред, а также нормально выдерживать воздействие ультрафиолета. Но давайте обо всем по порядку.
Расшифровка и структура провода РКГМ
Для того чтобы определиться с основными характеристиками провода, давайте разберемся, а из чего же собственно он состоит. В этом нам помогут аббревиатура его названия, а также краткий обзор его структуры.
Расшифровка РКГМ
Прежде всего, давайте разберемся с его аббревиатурой. Ведь только одно это уже скажет немало знающему человеку о характеристиках провода.
Расшифровка аббревиатуры проводов РКГМ
Итак:
- Первой буквой в обозначении любого провода должна быть «А». Это означает, что токопроводящая часть провода изготовлена из алюминия. Если этой буквы нет, как в нашем случае, то это значит, что токопроводящая часть изготовлена из меди. А это уже хорошо, так как медь обладает более высокими параметрами электропроводности и лучшими механическими характеристиками.
- Вторая буква у нас Р. Она указывает на тип изоляции провода. В нашем случае — это резиновая изоляция.
- Третья буква «К» указывает на особенности резины, применяемой для изоляции. «К» обозначает кремнийорганическая. Иногда ее еще называют силиконовой резиной. Именно эта особенность резины и придает ей многие положительные качества.
Класс гибкости провода
- Следующая буква «Г» указывает на гибкость провода. Как говорит инструкция, провод можно называть гибким, если он принадлежит как минимум к четвертому классу гибкости.
 Согласно ГОСТ 22483-77 всего таких классов 6 — и чем выше класс, тем выше гибкость провода.
Согласно ГОСТ 22483-77 всего таких классов 6 — и чем выше класс, тем выше гибкость провода. - Последней буквой в обозначении является «М». Она говорит нам о дополнительной оплетке провода, которая в нашем случае выполнена из стекловолокна. Для придания ему более качественных характеристик, стекловолокно дополнительно пропитывают лаком и эмалью.
Таблица сечений проводов РКГМ
- После буквенной маркировки, обычно указывается цифра. Она обозначает сечение изделия. Например, РКГМ 25 — провод с сечением в 25 мм2. Вообще, данный тип провода выпускается с номиналами от 0,75 мм2
Структура провода РКГМ
Еще больше о характеристиках провода мы сможем понять, если подробно разберем его структуру и материалы, используемые для его создания. Тем более что для данного провода применяются не совсем стандартные материалы.
Итак:
- Для любого провода в первую очередь важны его электрические качества в плане проводимости электрического тока.
 Как мы уже выяснили выше, РКГМ провод выполнен из меди. И он имеет не менее чем четвертый класс гибкости. А что это значит?
Как мы уже выяснили выше, РКГМ провод выполнен из меди. И он имеет не менее чем четвертый класс гибкости. А что это значит? - Класс гибкости четыре обозначает, что токоведущая часть представляет собой не единое целое, а скручена из отдельных проволок. Такая конструкция позволяет проводу многократно изгибаться без потери своих механических и электрических свойств.
- Кроме того, понятно, что чем большее количество проволок свито в один провод при одинаковом сечении, тем более подвижной будет токоведущая жила.
Нормы минимального сечения отдельных проволок для проводов РКГМ
- Именно поэтому ГОСТ нормирует минимальный диаметр каждой отдельной проволоки в проводе разного сечения. Например, возьмем РКГМ 1,5 — провод с классом гибкости 4. Для него диаметр каждой отдельной проволоки должен быть не выше 0,41 мм. А для провода сечением в 10 мм2, этот норматив уже будет 0,53 мм.
- Но данное правило применимо для всех гибких проводов. Далеко не все из них имеют резиновую кремнийорганическую изоляцию.
 В ней-то и кроется главная особенность провода. Такая изоляция не проводит электрический ток даже при температуре в 200⁰С. Для сравнения: обычная резина становится проводником уже при 120-150⁰С.
В ней-то и кроется главная особенность провода. Такая изоляция не проводит электрический ток даже при температуре в 200⁰С. Для сравнения: обычная резина становится проводником уже при 120-150⁰С.
На фото: пример использования РКГМ для выводов двигателей
- Еще одним положительным моментом является то, что при горении, которое наступает только при температуре в 600-700⁰С, такая изоляция не выделяет токсичных веществ. И даже если изоляция сгорит, то оставшийся на проводе диоксид кремния может выполнять роль диэлектрика как на видео.
Обратите внимание! Кремний диоксид, образующийся на токоведущей части после сгорания провода, очень хрупок и разрушается от малейшего прикосновения. Поэтому рассчитывать на такую изоляцию не стоит.
- В отличие от поливинилхлоридной изоляции такой диэлектрик не восприимчив к солнечному свету. При этом он достаточно неплохо переносит воздействие агрессивных сред — в том числе и озона. Единственным недостатком такой изоляции является ее цена, которая значительно выше того же ПВХ.

Зависимость толщины изоляции от сечения провода
- Толщина изоляции зависит от сечения провода. Обычно она составляет от 0,6 до 2 мм.
- Кроме самой изоляции, провод имеет еще и оплетку из стекловолокна. Эта оплётка пропитывается смесью глифталевого лака и кремнийорганической смолы. Такая пропитка позволяет стекловолокну выдерживать температуры до 250⁰С, а также повышает механические характеристики самой оплетки.
Характеристики провода РКГМ
Теперь можно поговорить и о характеристиках провода. Причем, многие из них мы уже раскрыли, и они основаны на применяемых для изготовления материалах. Но кроме стойкости к высоким температурам важны и чисто электрические, а также механические параметры.
Характеристики проводов РКГМ | Прежде всего, это электропроводность изделия. Она напрямую зависит от сечения провода. Так, РКГМ 10 провод будет иметь сопротивление не выше 2,00 Ом/км, а провод сечением в 25 мм2 не более 0,809 Ом/км. |
Номинальные показатели сопротивления изоляции РКГМ | Следующим важным критерием является изоляция провода. Она так же нормируется и зависит от сечения. Но в любом случае, 1 км провода должен иметь сопротивление изоляции не ниже 90 МОм. И это после трехчасового погружения в воду. |
Минимальный радиус изгиба провода | Еще одним важным параметром является гибкость провода. Она определяет, с каким радиусом изгиба по отношению к номинальному диаметру можно изгибать провод. Так вот для нашего провода, этот параметр составляет два номинальных диаметра. Это очень хороший показатель. Ведь даже у многих шнуров этот показатель не часто превышает 5. |
Номинальные характеристики РКГМ | Отдельно остановимся и на температурных характеристиках. Выше мы уже указывали предельно допустимые температуры для отдельных компонентов провода, но необходимо уточнить и его номинальные показатели. Так, максимально допустимая температура работы составляет 180⁰С. Минимально допустимая температура составляет -60⁰С. Но укладывать провод не следует при температуре ниже -15⁰С. |

Обратите внимание! Изгибать провод своими руками под углом в два номинальных диаметра, можно только до 10 раз подряд. При большем количестве изгибаний подряд, его оплетка начинает расслаиваться и терять свои свойства. Поэтому, повышенной гибкостью провода не следует злоупотреблять.
Вывод
РКГМ 2,5 — провод, который идеально подойдет для монтажа электропроводки в банях и саунах. Такой провод можно использовать в помещениях с повышенной влажностью, обязательно следует использовать в пожароопасных помещениях, а также применять в качестве выводов машин с повышенным нагревом.
Кстати, его часто применяют в качестве выводов электродвигателей, трансформаторов и других электрических машин. Это связано с тем, что такие контактные соединения часто подвержены нагреву, и провода РКГМ обеспечивают защиту от возгорания.
Это связано с тем, что такие контактные соединения часто подвержены нагреву, и провода РКГМ обеспечивают защиту от возгорания.
Провод ркгм: характеристики и особенности использования
Характеристики проводов ПГВА
ПГВА провод нашел широкое применение в первую очередь в автомобильной промышленности. Его используют для прокладки проводки в автомобилях, тракторах, мопедах, а также других механизмах и устройствах.
Основным его достоинством является повышенная гибкость и устойчивость к таким агрессивным средам как бензин, масло и дизельное топливо. Но давайте обо всем по порядку.
Способ изготовления и технические параметры провода
Для начала давайте расшифруем его название. П – это провод, Г – повышенной гибкости, В – изоляция проводника которая выполнена из поливинилхлоридного (ПВХ) пластика, а А – означает автотракторное назначение провода.
Способ изготовления провода
Производство провода ПГВА организовано только в одножильном исполнении. Материал изготовления токоведущих жил – медь.
Материал изготовления токоведущих жил – медь.
Схема проводов ПГВА
- Одним из главных преимуществ провода является его гибкость. Для этого токоведущую жилу создают методом скручивания нескольких проволок меньшего диаметра.
- Например, для создания провода сечением 0,5 мм2 используют не менее семи проводов диаметром не более 0,31 мм. А для создания провода сечением в 95 мм2 скручивают не менее 19 проводов диаметром до 0,83 мм.
На фото разнонаправленно скрученные повивы провода
- В соответствии с п.2.3ГОСТ 22483 эти провода в зависимости от сечения могут иметь несколько повивов. Обычно эти повивы скручивают в противоположные стороны. Но по желанию заказчика возможно одностороннее скручивание повивов.
- Как гласит инструкция обрыв нескольких проводов в повиве так же не является нарушением. Главное, чтоб остаточное сопротивление жил соответствовало ГОСТ 22483.
- Форма провода обычно имеет круглую форму. Но по желанию заказчика завод-изготовитель может производить провода ПГВА и овальной формы.
 В некоторых случаях это может быть удачным решением для более скрытого монтажа.
В некоторых случаях это может быть удачным решением для более скрытого монтажа.
Изоляция проводов ПГВА
- Поверх токоведущей части выполняется заливка поливинилхлоридной изоляции. Изоляция должна быть нанесена плотно и не иметь воздушных пробок. Ее толщина нормируется ГОСТ 23286-78 и варьирует от 0,6 до 1,6 мм.
- Сопротивление изоляции провода подвергается проверочным испытаниям. Напряжение для испытаний составляет не менее 1,5кВ, а время, в течении которого изоляция провода должна выдерживать это напряжение, составляет не менее 5 минут.
Технические параметры провода
Провод автомобильный ПГВА имеет ряд преимуществ в том числе и перед своим собратом – проводом ПВА. Поэтому для наглядности давайте рассмотрим их технические характеристики в сравнении.
Характеристики проводов ПГВА
Итак:
- Одной из основных характеристик является номинальное напряжение, для которого рассчитан провод. Для проводов обеих марок оно составляет 48В.

Сравнительные характеристики провода ПВА и ПГВА
- Вторым важным параметром является электрическое сопротивление провода. Оно так же практически не отличается и в зависимости от сечения провода может быть лучше у одного или другого типа провода. Например, для сечения провода в 1 мм2 сопротивление ПВА составляет 19,5 Ом, а для ПГВА – 19,8 Ом.
А вот номинальные характеристики по условиям изгиба у проводов ПГВА выгодно отличаются. Такой провод можно изгибать радиусом кратным 10 его диаметрам. В то же время провод ПВА допускается изгибать только с радиусом кратным 20 его диаметрам.
Гибкость проводов ПГВА
- По условиям окружающей среды ПГВА так же имеет определённые достоинства. Дело в том, что провод ПВА выпускается только для умеренного и тропического климата. С температурными показателями от -40⁰С до +105⁰С. А вот ПГВА может быть изготовлен в климатическом исполнении для арктических зон. В этом случае его минимальная температура составляет до -60⁰С.

В остальном провода достаточно похожи. Оба вида достаточно просты в монтаже своими руками, предназначены для работы с относительной влажностью до 90%, имеют стойкость к растрескиванию и образованию грибка, а также не поддерживают горение при одиночной прокладке.
Обратите внимание! Номинальные параметры относительной влажности для работы, в которой предназначен провод измерены для температуры в 27⁰С. Некоторые продавцы идут на ухищрения и указывают относительную влажность для более высоких температур.
Варианты поставки провода
Цена на провод может отличатся в зависимости от способа его поставки конечному потребителю. Это зависит от сечения провода и договорённостей между производителем и покупателем.
Бухта ПГВА | Обычно провод поставляется в бухтах. Их длина для провода с сечением от 0,2 до 25 мм2 составляет до 100 метров. Для проводов же сечением до 95 мм2 длина провода обычно не меньше 50 метров. |
Варианты поставки проводов ПГВА | Вес бухты обычно не превышает 25кг. В некоторых случаях в бухте могут быть провода длиной более 10 метров, но менее стандартных. Но суммарная масса таких провод не может превышать 5% от суммарного объема поставок. |
Цветовая палитра проводов ПГВА | Отдельным вопросом является цвет провода. Как вы можете видеть на видео он может варьировать в достаточно широких пределах. Это зависит от договорённостей между производителем и покупателем. |
Гарантия на провода ПГВА | Гарантийный срок службы такого провода составляет не менее 3 трех лет. В то же время срок службы для провода составляет 10 лет. На практике же он служит гораздо дольше. |

Обратите внимание! Согласно норм ПУЭ каждый проводник должен иметь цветовую маркировку, соответствующую сфере его применения. Так согласно п.1.1.30 ПУЭ для маркировки положительного провода в сети постоянного тока следует использовать красный цвет.
Для маркировки отрицательного проводника – синий. В связи с тем, что ПГВА это автомобильный провод преимущественно используется именно эта расцветка.
Вывод
ПГВА провода являются хорошим вариантом для электропроводки автомобиля и другого движимого имущества. А технические и эксплуатационные характеристики позволяют применять его для решения широкого спектра задач. Поэтому провода ПГВА можно рекомендовать к применению не только в сфере автомобиле строения.
% PDF-1.6
%
295 0 объект>
endobj
xref
295 86
0000000016 00000 н.
0000003596 00000 н.
0000003754 00000 н.
0000003882 00000 н.
0000003939 00000 н.
0000004507 00000 н.
0000004643 00000 п.
0000004778 00000 н.
0000004915 00000 н.
0000006092 00000 н.
0000006272 00000 н.
0000007317 00000 н.
0000008493 00000 п.
0000009144 00000 п. 0000010116 00000 п.
0000011291 00000 п.
0000012286 00000 п.
0000013255 00000 п.
0000013322 00000 п.
0000013703 00000 п.
0000013758 00000 п.
0000021968 00000 п.
0000022161 00000 п.
0000022562 00000 п.
0000022989 00000 п.
0000030680 00000 п.
0000030871 00000 п.
0000031248 00000 н.
0000031421 00000 п.
0000031641 00000 п.
0000031828 00000 п.
0000037927 00000 н.
0000038123 00000 п.
0000038526 00000 п.
0000039444 00000 п.
0000040401 00000 п.
0000041344 00000 п.
0000042315 00000 п.
0000043252 00000 п.
0000044290 00000 п.
0000044483 00000 п.
0000045473 00000 п.
0000045763 00000 п.
0000054148 00000 п.
0000054347 00000 п.
0000054797 00000 п.
0000055973 00000 п.
0000056889 00000 п.
0000056942 00000 п.
0000058274 00000 п.
0000058454 00000 п.
0000058774 00000 п.
0000058927 00000 н.
0000058972 00000 н.
0000060129 00000 п.
0000060643 00000 п.
0000061648 00000 п.
0000061842 00000 п.
0000062608 00000 п.
0000063311 00000 п.
0000063500 00000 п.
0000066126 00000 п.
0000010116 00000 п.
0000011291 00000 п.
0000012286 00000 п.
0000013255 00000 п.
0000013322 00000 п.
0000013703 00000 п.
0000013758 00000 п.
0000021968 00000 п.
0000022161 00000 п.
0000022562 00000 п.
0000022989 00000 п.
0000030680 00000 п.
0000030871 00000 п.
0000031248 00000 н.
0000031421 00000 п.
0000031641 00000 п.
0000031828 00000 п.
0000037927 00000 н.
0000038123 00000 п.
0000038526 00000 п.
0000039444 00000 п.
0000040401 00000 п.
0000041344 00000 п.
0000042315 00000 п.
0000043252 00000 п.
0000044290 00000 п.
0000044483 00000 п.
0000045473 00000 п.
0000045763 00000 п.
0000054148 00000 п.
0000054347 00000 п.
0000054797 00000 п.
0000055973 00000 п.
0000056889 00000 п.
0000056942 00000 п.
0000058274 00000 п.
0000058454 00000 п.
0000058774 00000 п.
0000058927 00000 н.
0000058972 00000 н.
0000060129 00000 п.
0000060643 00000 п.
0000061648 00000 п.
0000061842 00000 п.
0000062608 00000 п.
0000063311 00000 п.
0000063500 00000 п.
0000066126 00000 п. 0000070900 00000 п.
0000074798 00000 п.
0000075231 00000 п.
0000075409 00000 п.
0000075464 00000 п.
0000077219 00000 п.
0000077400 00000 п.
0000077823 00000 п.
0000077997 00000 п.
0000078590 00000 п.
0000078769 00000 п.
0000078825 00000 п.
0000079066 00000 п.
0000079176 00000 п.
0000079326 00000 п.
0000079503 00000 п.
0000079668 00000 н.
0000079837 00000 п.
0000080042 00000 п.
0000080197 00000 п.
0000080332 00000 п.
0000080473 00000 п.
0000080629 00000 п.
0000002016 00000 н.
трейлер
] >>
startxref
0
%% EOF
380 0 obj> поток
xb«b`c`g` Ȁ
0000070900 00000 п.
0000074798 00000 п.
0000075231 00000 п.
0000075409 00000 п.
0000075464 00000 п.
0000077219 00000 п.
0000077400 00000 п.
0000077823 00000 п.
0000077997 00000 п.
0000078590 00000 п.
0000078769 00000 п.
0000078825 00000 п.
0000079066 00000 п.
0000079176 00000 п.
0000079326 00000 п.
0000079503 00000 п.
0000079668 00000 н.
0000079837 00000 п.
0000080042 00000 п.
0000080197 00000 п.
0000080332 00000 п.
0000080473 00000 п.
0000080629 00000 п.
0000002016 00000 н.
трейлер
] >>
startxref
0
%% EOF
380 0 obj> поток
xb«b`c`g` Ȁ
Выборка квоты: определение, типы, примеры, шаги и многое другое
Что такое квотная выборка?
Квотная выборка определяется как метод не вероятностной выборки, при котором исследователи создают выборку с участием лиц, представляющих совокупность.Исследователи выбирают этих людей по определенным чертам или качествам. Они принимают решение и создают квоты, чтобы образцы маркетинговых исследований могли быть полезны при сборе данных. Эти выборки могут быть обобщены на всю совокупность. Окончательная подгруппа будет определена только в зависимости от того, насколько интервьюер или исследователь знает население.
Эти выборки могут быть обобщены на всю совокупность. Окончательная подгруппа будет определена только в зависимости от того, насколько интервьюер или исследователь знает население.
Например, сигаретная компания хочет выяснить, какая возрастная группа предпочитает сигареты какой марки в конкретном городе. Он / она применяет квоты для возрастных групп 21-30, 31-40, 41-50 и 51+.На основании этой информации исследователь определяет тенденцию к курению среди населения города.
Выберите респондентов
Типы квотной выборки:
Выборка квот может быть двух видов — выборка контролируемых квот и неконтролируемая выборка квот. Вот что они означают:
Контролируемая выборка квот:
Контролируемая квотная выборка накладывает ограничения на выбор исследователем выборки. Здесь исследователь ограничивается отбором образцов.
Неконтролируемая выборка квот:
Неконтролируемая квотная выборка не накладывает никаких ограничений на выбор исследователем образцов. Здесь исследователь по желанию выбирает членов выборки.
Здесь исследователь по желанию выбирает членов выборки.
Пример выборки квоты:
Давайте посмотрим на базовый пример выборки квот:
Исследователь хочет опросить людей о том, какой бренд смартфонов они предпочитают использовать. Он считает, что размер выборки составляет 500 респондентов. Кроме того, он / она интересуется только обследованием десяти штатов США.Вот как исследователь может разделить население по квотам:
- Пол: 250 мужчин и 250 женщин
- Возраст: 100 респондентов в возрасте 16-20, 21-30, 31-40, 41-50 и 51+
- Статус занятости: 350 занятых и 150 безработных.
- (Исследователи применяют дополнительные вложенные квоты. Например, из 150 безработных 100 должны быть студентами.)
- Местоположение: 50 ответов на состояние
В зависимости от типа исследования исследователь может применять квоты на основе структуры выборки.Исследователю необязательно делить квоты поровну.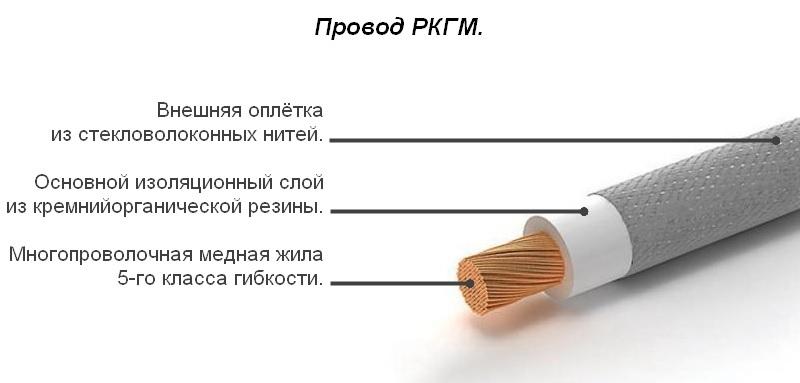 Он / она делит квоты в соответствии со своими потребностями (как показано в примере, где исследователь опрашивает 350 работающих и только 150 безработных). Для связи с респондентами может проводиться случайная выборка.
Он / она делит квоты в соответствии со своими потребностями (как показано в примере, где исследователь опрашивает 350 работающих и только 150 безработных). Для связи с респондентами может проводиться случайная выборка.
Выберите респондентов
Как выполнить квотную выборку:
Методы вероятностной выборки включают в себя значительное количество правил, которым исследователь должен следовать при формировании выборки.Но, поскольку выборка по квотам — это метод не вероятностной выборки, правил для формального создания выборок нет. Обычно выборка квот состоит из четырех шагов. Вот шаги:
- Разделите совокупность выборки на подгруппы: При стратифицированной выборке исследователь разделяет всю совокупность на взаимно исчерпывающие подгруппы, то есть элементы каждой из подгрупп становятся частью только одной из этих подгрупп. Здесь исследователь применяет случайный выбор.
- Определите вес подгрупп: Исследователь оценивает пропорцию, в которой подгруппы существуют в популяции.
 Он / она поддерживает эту пропорцию в выборке, отобранной с использованием этого метода выборки.
Он / она поддерживает эту пропорцию в выборке, отобранной с использованием этого метода выборки. - Например, если 58% людей, заинтересованных в покупке наушников Bluetooth, относятся к возрастной группе 25–35 лет, в ваших подгруппах также должно быть такое же процентное соотношение людей, принадлежащих к соответствующей возрастной группе.
- Выберите подходящий размер выборки: На третьем этапе исследователь должен выбрать размер выборки, сохраняя пропорцию, оцененную на предыдущем этапе.Если размер генеральной совокупности составляет 500, исследователь может выбрать выборку из 50 элементов.
Выборка, выбранная после выполнения первых трех шагов, должна представлять целевую совокупность. - Проведите опросы в соответствии с определенными квотами: убедитесь, что соблюдаете заранее определенные квоты, чтобы добиться реальных результатов. Не опрашивайте заполненные квоты и сосредотачивайтесь на заполнении опросов для каждой квоты.
Характеристики квотной выборки:
Вот десять основных характеристик квотной выборки
- Нацелен на лучшее представительство респондентов в окончательной выборке.

- Квоты в реальном смысле воспроизводят интересующую нас совокупность.
- Полученные оценки более репрезентативны.
- Качество выборок квот варьируется.
- Сохраняет время сбора данных исследования, поскольку выборка представляет генеральную совокупность.
- Экономия затрат на исследования, если квоты точно отражают численность населения.
- Он отслеживает количество типов людей, принимающих участие в опросе.
- Исследователь всегда делит население на подгруппы.
- Выборка представляет все население.
- Исследователи используют метод выборки для определения черт определенной группы людей.
Преимущества квотной выборки
Вот четыре основных преимущества квотной выборки
- Экономия времени: Из-за наличия квоты на создание выборки этот процесс выборки является быстрым и простым.
- Удобство исследования: Использование квотной выборки и соответствующих исследовательских вопросов, интерпретация информации и ответов на опрос — очень удобный процесс для исследователя.

- Точное представление интересующей совокупности: Исследователи эффективно представляют совокупность, используя этот метод выборки. Здесь нет места для чрезмерного представительства, поскольку этот метод выборки помогает исследователям изучать население с использованием определенных квот.
- Экономия денег: Бюджет, необходимый для выполнения этого метода выборки, минимален.
Выберите респондентов
Заявки на квотную выборку:
Ниже приведены примеры применения и использования квотной выборки.
- В ситуациях, когда у исследователей есть определенные критерии для проведения исследования, он позволяет выбирать подгруппы, благодаря чему исследователям становится чрезвычайно удобно получать желаемые результаты. Признак или характеристика могут быть фильтром для формирования подгруппы.
- Исследователь использует этот метод, когда он / она ограничены во времени. Применение квот позволяет исследователю за очень короткое время получить представление обо всей интересующей его группе населения.

- Квоты применяются при ограниченном бюджете исследователя.Вместо того чтобы исследовать большую популяцию, исследователь экономит деньги, используя несколько квот, чтобы получить полную картину населения.
- Некоторые исследования не требуют высокой точности из-за характера исследовательского проекта. Он идеально подходит для применения в выборке квот для этих исследований.
Отбор проб с помощью QuestionPro Audience
QuestionPro Audience поддерживает обширный пул из более чем 22 миллионов респондентов по всему миру. Вам нужно применить жесткие квоты к вашему опросу? Или вы ищете конкретную нишевую исследовательскую аудиторию? Мы можем помочь вам выполнить эти жесткие квоты и выйти на нишевых экспертов, чтобы вы получили точные и действенные результаты для своего следующего исследования.Попробуйте QuestionPro Audience сегодня, чтобы найти креативные решения для вашего бизнеса.
Описание блока— Документация NVDLA
(Примечание: эта версия Описание блока описывает NVDLA
дизайн в том виде, в котором он присутствует в версии nvdlav1. Остальные релизы и
конфигурации аналогичны, но не содержат всех функций и размеров
элементов оборудования могут отличаться.)
Остальные релизы и
конфигурации аналогичны, но не содержат всех функций и размеров
элементов оборудования могут отличаться.)
Мост DMA
Обзор
Входные изображения и обработанные результаты хранятся во внешней памяти DRAM, но пропускная способность и задержка внешней DRAM обычно недостаточны для позволяют NVDLA полностью использовать MAC-массивы.Поэтому NVDLA сконфигурирован с дополнительным интерфейсом памяти к встроенной SRAM.
Чтобы использовать встроенную SRAM, NVDLA необходимо перемещать данные между внешними DRAM. и SRAM. Мост DMA предлагается полностью заполнить эту цель. Есть два независимые пути, один — копирует данные из внешней DRAM во внутреннюю SRAM, а другой — копирует данные из внутренней SRAM во внешнюю. DRAM. Оба направления не могут работать одновременно. BDMA также может перемещать данные из внешней DRAM во внешнюю DRAM или из внутренней SRAM во внутреннюю SRAM.
Bridge DMA имеет два интерфейса DMA, один подключается к внешней памяти DRAM и
другой подключается к внутренней SRAM. Оба интерфейса поддерживают чтение
и писать запросы. Ширина данных обоих интерфейсов составляет 512 бит, а
максимальная длина пакета — 4.
Оба интерфейса поддерживают чтение
и писать запросы. Ширина данных обоих интерфейсов составляет 512 бит, а
максимальная длина пакета — 4.
Чтобы переместить все данные в куб, повторяется строка поддержки BDMA, которая может выбрать несколько строк с адресными переходами между строками, отразить поверхность. Кроме того, BDMA будет поддерживать еще один уровень повтора, который выборка нескольких строк может повторяться, что отражает несколько поверхности, отражают куб.
Рис.39 Мост DMA
Конволюционный конвейер
Обзор
Конвейер свертки — один из конвейеров базовой логики NVDLA. Он используется для ускорения алгоритма свертки. Он поддерживает комплексные программируемые параметры для переменных размеров свертки. Некоторые особенности как Winograd и multi-batch применяются в конвейере свертки для улучшить производительность и повысить эффективность MAC.
Конвейер свертки имеет пять этапов, а именно: DMA свертки,
Буфер свертки, Контроллер последовательности свертки, MAC свертки и
Накопитель свертки. Их также называют CDMA, CBUF, CSC, CMAC и
CACC соответственно. Каждый этап имеет свой собственный подчиненный порт CSB для получения конфигурации.
данные от управляющего ЦП. Используется единый механизм синхронизации
по всем этапам.
Их также называют CDMA, CBUF, CSC, CMAC и
CACC соответственно. Каждый этап имеет свой собственный подчиненный порт CSB для получения конфигурации.
данные от управляющего ЦП. Используется единый механизм синхронизации
по всем этапам.
Конвейер свертки поддерживает три типа операций. Их:
Прямая свертка для данных функций или режим постоянного тока
Свертка ввода изображения или режим ввода изображения
Свертка Винограда или режим Винограда
Конвейер свертки содержит 1024 MAC для int16 или fp16, а также массив из 32 элементов для хранения частичной суммы.В Ресурсы MAC также могут быть настроены для предоставления 2048 MAC для int8. Кроме того, в буфере свертки имеется 512 КБ SRAM, что обеспечивает входной вес и хранение активации. Эти устройства подробно описаны ниже. в этом документе.
Ниже представлена схема конвейера свертки.
Рис. 40 Конволюционный конвейер
Прямая свертка
Конвейер свертки всегда имеет две части входных данных. Один ввод
данные активации, другой — данные веса.Предположим, движок NVDLA имеет такой
входные параметры:
Один ввод
данные активации, другой — данные веса.Предположим, движок NVDLA имеет такой
входные параметры:
Размер куба данных элемента: Ш x В x C
Размер ядра на одну массу: R x S x C
Общее количество ядер: K
Нулевой размер заполнения: LP на левой границе, RP на правой границе, TP на верхней границе, BP на нижней границе.
Шаг свертки: SX по оси X, SY по оси Y
Расширение: DX по оси X, DY по оси Y
Размер куба выходных данных: W ’ x H’ x C ’
Рис.41 Операция свертки
На рисунке ниже показан шаг свертки и нулевое заполнение.
Рис.42 Шаг свертки и заполнение нулями
Тогда уравнения этих параметров:
\ [S ^ {‘} = \ left (S — 1 \ right) \ times DX + 1 \]
\ [R ^ {‘} = \ left (R — 1 \ right) \ times DY + 1 \]
\ [W ^ {‘} = \ frac {LP + W + RP — S’} {\ text {SX}} + 1 \]
\ [H ^ {‘} = \ frac {TP + H + BP — R’} {\ text {SY}} + 1 \]
\ [C ^ {‘} = K \]
Взаимосвязь каждого элемента y в кубе выходных данных, элемент x в куб входных данных признаков и элемент wt в ядрах веса:
\ [y_ {w, \ h, \ k} = \ \ sum_ {r = 0} ^ {R — 1} {\ sum_ {s = 0} ^ {S — 1} {\ sum_ {c = 0} ^ {C — 1} {x _ {(w * SX — LP + r), (h * SY — TP + s), \ c} * \ text {wt} _ {r, s, \ c, k}}} } \]
Координаты w, h, c, k в приведенных выше уравнениях начинаются с нуля.
Для выполнения операции свертки в приведенном выше уравнении Конвейер свертки использует метод , прямая свертка . Ключ идея прямой свертки состоит в том, чтобы отделить операции умножения от каждое ядро свертки на группы, каждая группа содержит 64 умножения. Основные правила:
Распределите все оборудование MAC на 16 субблоков. Один дополнительный блок называется MAC Cell и имеет оборудование для 64 MAC адресов int16 / fp16 или для 128 MAC-адресов int8.
Набор ячеек MAC называется массивом ячеек MAC.
Разделите все кубы входных данных на маленькие кубики размером 1x1x64 для int16, fp16 и int8.
Разделите все кубы весовых данных на маленькие кубики размером 1x1x64 для int16, fp16 и int8.
Умножьте один небольшой куб входных данных на один небольшой куб данных веса, и складывать продукты вместе. Эти умножения и сложения выполняется в пределах одной ячейки MAC.
Объедините эти вычислительные операции в 4 уровня операций, которые являются атомарными.
 операция, операция полосы, операция блока и операция канала.
операция, операция полосы, операция блока и операция канала.
Четыре операции описаны ниже на примере режима int6 percision.
Атомная операция
Атомарная операция — это базовый шаг для прямой свертки. В одном атомном операции, каждая ячейка MAC кэширует один кубик веса 1x1x64 из индивидуальное весовое ядро. Таким образом, 16 MAC-ячеек имеют вес кеша из 16 ядра int16 / fp16 или 32 ядра int8.{min (c + 63, \ C — 1)} {x _ {(w * SX — LP + r), (h * SY — TP + s), \ i} * \ text {wt} _ {r, \ s, \ i, k}} \]
В уравнении PS относится к частичной сумме. Переменная c всегда делится на 64.
Схема, показывающая атомарную операцию, приведена ниже.
Рис.43 Атомная операция
Операция с полосой
Операция с полосой объединяет группу атомарных операций из нескольких
извилины. Во время одной операции полосы весовые данные в ячейке MAC
массив остается без изменений.Входные данные перемещаются по кубу входных данных.
Обратите внимание, что частичные суммы за одну операцию полосы не могут быть добавлены вместе, поскольку соответствуют разным точкам выходного куба.
Длина операции полосы пропускания имеет ограничения. Нижний предел 16 равен из-за внутренней пропускной способности для выборки весов для следующей операции чередования. Верхний предел равен 32 из-за размера буфера в аккумуляторе. В в некоторых крайних случаях длина может быть меньше нижнего предела.
На рисунке ниже показан пример работы полосы, содержащей 16 атомарные операции.В этом случае размер заполнения равен 0. Обратите внимание, это не прогрессивное сканирование куба входных данных. Хотя обычно полоска сначала сканирует по ширине w. На рисунке ниже показан пример без отступов, поэтому последние два столбца не являются частью первой полосы (с ядром 3×3, без заполнения и входом с w = 6, вывод будет имеют w равное 4).
Рис.44 Работа с полосой
Блок операции
Операция блока — операция более высокого уровня, состоящая из нескольких
полосовые операции. Во время блока
Операция, каждое ядро в группе ядер использует RxSx64
весовые элементы, вместе с
небольшой куб входных данных функции, размер которого должен соответствовать
результаты могут складываться между операциями с полосами и накапливаться в
аккумулятор 16-32 элементов.
Во время блока
Операция, каждое ядро в группе ядер использует RxSx64
весовые элементы, вместе с
небольшой куб входных данных функции, размер которого должен соответствовать
результаты могут складываться между операциями с полосами и накапливаться в
аккумулятор 16-32 элементов.
Рис.45 Работа блока
Все операции с полосами в одной блочной операции имеют одинаковые атомарные номер операции. Частичные суммы той же операции блока равны суммируются для каждой операции полосы в накопителе свертки.{min (c + 63, \ C — 1)} {x _ {(w * SX — LP + r), (h * SY — TP + s), \ i} * \ text {wt} _ {r, \ s, \ i, k}}}} \]
В уравнении AS относится к накопительной сумме. Переменная c всегда делится на 64.
Работа канала
Работа с каналом — это операция еще более высокого уровня. Оно включает (C + 63) / 64 блочных операций. Блочные операции в одном канале операции аналогичны, за исключением того, что координата направления канала разные, как показано ниже
Рис. {min (c + 63, \ C — 1)} {x _ {(w * SX — LP + r), (h * SY — TP + s), \ (i * 64 + j)} * \ text {wt } _ {r, \ s, \ (i * 64 + j), k}}}}} \]
{min (c + 63, \ C — 1)} {x _ {(w * SX — LP + r), (h * SY — TP + s), \ (i * 64 + j)} * \ text {wt } _ {r, \ s, \ (i * 64 + j), k}}}}} \]
Это уравнение идентично исходному уравнению свертки. для полосы из 16-32 точек вывода. После одной операции канала аккумулятор выгружается и отправляется на постпроцессор, освобождая место для следующая операция канала.
Групповая работа
Групповая операция — это операция более высокого уровня, чем операция канала. Это включает около int ((dataout_height * dataout_width) / stripe_size) канальные операции.После групповой операции выходные данные составляют W x H x K ’выходная поверхность. Здесь K ’означает размер ядра в ядре. группа, где одна группа ядер — это количество ядер, обрабатываемых за раз, по одному на ячейку MAC.
Выходная последовательность
Последовательность, указанная в каждой операции, в основном предназначена для функции ввода.
данные и данные веса, но не выходная последовательность. Выходные данные
последовательность довольно проста. Он следует порядку C ’(K’) -> W-> H-> C (K).
Здесь C ’или K’ относится к размеру группы ядра, который равен 16 для int16 / fp16.
и 32 для int8.
Он следует порядку C ’(K’) -> W-> H-> C (K).
Здесь C ’или K’ относится к размеру группы ядра, который равен 16 для int16 / fp16.
и 32 для int8.
Порядок вывода прямой свертки соответствует памяти функций порядок отображения.
Рис.47 Выходная последовательность раздела
Операция для Int8 и fp16
Упомянутые выше операции отражают точность int16. Fp16 — это обрабатывается идентично. Однако int8 обрабатывается немного иначе.
В конвейере свертки каждый примитив умножения-накопления для int16 / fp16 разделен на два MAC для int8. Пропускная способность элемента int8 равна поэтому удвойте пропускную способность элемента int16.
В таблице ниже записаны параметры одной атомарной операции.
Свертка Точность | Входные данные Элементы | Веса на Ядро | Ядра | Выход Элементы |
|---|---|---|---|---|
int16 | 64 | 1024 | 16 | 16 |
fp16 | 64 | 1024 | 16 | 16 |
внутр8 | 64 | 2048 | 32 | 32 |
Свертка Винограда
Свертка Винограда относится к необязательному алгоритму для оптимизации
выполнение прямой свертки. {T} \ text {dC} \ right) \ right \ rbrack A \]
{T} \ text {dC} \ right) \ right \ rbrack A \]
Здесь символ ⊙ указывает на поэлементное умножение.Символ г — это 3×3 ядро и d — это тайл 4×4 куба входных данных. Символ S — это результат свертки г, и д. Это матрица 2×2.
\ [\ begin {split} g = \ begin {bmatrix} \ text {wt} _ {0,0} & \ text {wt} _ {0,1} & \ text {wt} _ {0,2} \\ \ text {wt} _ {1,0} & \ text {wt} _ {1,1} & \ text {wt} _ {1,2} \\ \ text {wt} _ {2,0} & \ text {wt} _ {2,1} & \ text {wt} _ {2,2} \\ \ end {bmatrix} \ end {split} \]
\ [\ begin {split} d = \ begin {bmatrix} x_ {0,0} & x_ {0,1} & x_ {0,2} & x_ {0,3} \\ x_ {1,0} и x_ {1,1} и x_ {1,2} и x_ {1,3} \\ x_ {2,0} & x_ {2,1} & x_ {2,2} & x_ {2,3} \\ x_ {3,0} & x_ {3,1} & x_ {3,2} & x_ {3,3} \\ \ end {bmatrix} \ end {split} \]
A , G и C — это матрицы для преобразования веса и входного признака
данные.{T} \) преобразует ядро 3×3 в ядро 4×4, используемое для точечной
умножение на патч 4×4 входного активационного куба. {T} \)
и С .{T} \).
Результатом фазы 2 является 8 частичных сумм или матрица 4×2.
{T} \)
и С .{T} \).
Результатом фазы 2 является 8 частичных сумм или матрица 4×2.
Фаза 3, каждая матрица частичной суммы 4×2 из фазы 2 умножается с матрицей А . Результат — 4 частичные суммы.
Затем 4 частичных суммы сохраняются в аккумуляторе для дальнейшего расчета. И фаза 2, и фаза 3 называются POA.
РежимWinograd также имеет пять операций. Сравнение параметров перечислены в таблице ниже.
режим | прямой свертка | прямой свертка | Виноград | Виноград |
|---|---|---|---|---|
форматы | внутр16 / fp16 | внутр8 | внутр16 / fp16 | внутр8 |
малые данные куб на MAC ячейка | 1x1x64 | 1x1x64 | 4x4x4 | 4x4x4 |
ядер на атомный операция | 16 | 32 | 16 | 32 |
атомикс операция за полосу операция | 16 ~ 32 | 16 ~ 32 | 16 ~ 32 | 16 ~ 32 |
полосы операция за блок операция | R * S | R * S | 1 | 1 |
блоков операция на канал операция | С / 64 | С / 64 | С / 4 | С / 4 |
Выходная последовательность свертки Винограда аналогична прямой
свертка. Некоторые отличия Винограда:
Некоторые отличия Винограда:
Для работы Winograd ширина и высота вывода должны быть делится на 4. Это обязательное требование. Это для специального сканирования заказ.
Порядок сканирования полосы в свертке Винограда: отличается от прямой свертки. См. Рисунок ниже.
Операция блока всегда имеет только одну операцию полосы.
Слой Винограда всегда выводит 4 строки параллельно.SDP гарантирует исправление отображения памяти куба выходных данных.
Рис. 48 Порядок сканирования полосы в Винограде (проекция Ш-В)
Деконволюция
Деконволюция — это разновидность специальной свертки. Это своего рода обратная операция нормальной свертки. В отличие от обычного случая свертки, слой деконволюции всегда увеличивает куб данных после расчета.
В архитектуре NVDLA деконволюция — это функция ПО. От HW
В перспективе слой SW-деконволюции состоит из последовательной свертки
слой и слой контракта, поддерживаемые блоком РУБИК. {C — 1} {DAIN _ {(w + x + 1 — S, h + y + 1 — R, \ z)} * W _ {(S — 1 — x, R — 1 — y, z, k)} }}} \]
{C — 1} {DAIN _ {(w + x + 1 — S, h + y + 1 — R, \ z)} * W _ {(S — 1 — x, R — 1 — y, z, k)} }}} \]
Согласно уравнению, 3D-деконволюция равна свертке с заполнением нулями (S-1) и (R-1) и обратным порядком веса R / S
Рис. 49 Одномерная деконволюция, шаг x = 1
Если шаг деконволюции X или Y не равен 1, поток вычислений немного другое. Ядра веса разбиты на меньшие наборы ядер. Каждый набор ядер работает как сверточный слой, где шаги X и Y равно 1.Поэтому несколько сверточных слоев используются для создания результат слоя деконволюции.
После последовательного сверточного слоя все значения результатов деконволюции готов, но порядок сопоставления не является ожидаемым результатом. Если мы добавим сверточный выходной куб один за другим в направлении C, затем куб итоговых выходных данных — это куб данных с расширенным каналом Винограда. В параметр расширения — это deconv_x_stride и deconv_y_stride.
Итак, NVDLA использует специальный слой контракта (выполняется Рубиком)
чтобы переупорядочить эти выходные значения, чтобы получить желаемый куб деконволюции.
В заключение, NVDLA поддерживает уровень деконволюции по следующей стратегии:
NVDLA использует два шага для выполнения слоя деконволюции, который больше 1
Первый шаг — это последовательные сверточные слои с обратным порядком ядра.
Вывод первого шага формирует вывод Винограда с расширенным каналом. куб данных. Параметр расширения — деконволюция x шаг и деконволюция у шага.
Вторая ступень работает на установках РУБИК.
Блок Рубика выполняет операцию, обратную Винограду, расширенному каналу куб данных.
После второго HW-уровня куб выходных данных формируется в соответствии с ожидаемым результатом.
Свертка с вводом изображения
NVDLA поддерживает свертку с данными изображения в специальном режиме для
улучшить использование MAC. Здесь данные изображения могут быть
часть или вся поверхность изображения. Однако NVDLA может поддерживать его только для
прямая свертка. DC , Виноград и слой деконволюции не могут
использовать форматы пикселей .Многопакетный вариант также не поддерживается для
ввод изображения.
По сравнению с DC, случай ввода изображения немного отличается:
Предварительное расширение канала. Весовое ядро должно делать канал предварительное расширение. Это не похоже на режим DC или режим Winograd.
Отображение данных в буфере свертки. Отображение данных изображения в буфер свертки отличается от режима DC и Winograd. Все элементы слева и справа заполнение и строка входных пикселей компактно находятся в записях CBUF.См. Рисунок ниже. Если размер канала равен 4, порядок отображения элементов следующий. R (Y) -> G (U) -> B (V) -> A (X). Если размер канала 3, порядок R (Y) -> G (U) -> B (V).
Распределение полосовой операции. Рабочая длина полосы составляет исправлено на 64. И операция полосы никогда не должна пересекать линии. Так что каждая операция полосы начинается с первого байта записи CBUF.

Используйте пост-расширение канала для ускорения. Даже с каналом до расширения, обычно размер канала ядра меньше 32.Следовательно, пост-расширение канала очень полезно для ввода изображений. сверточный слой.
Рис.50 Отображение пикселей в буфере свертки
После расширения канала
Пост-расширение канала — это опция для улучшения использования MAC для свертка с вводом изображения.
В конвейере свертки для одной атомарной операции требуется 64 элемента в размер канала (исключая режим Винограда). Если размер канала входа куб данных меньше 64, MAC-адреса не используются на 100% в каждом цикле.Таким образом, эффективность MAC зависит от размера канала в режиме постоянного тока и ввода изображения. Режим.
Основная идея пост-расширения канала — вертикальное расширение. для увеличения размера канала во время выполнения.
Например, входной слой изображения имеет размер ядра 4x4x4. Если
пост-расширение не включено, размер предварительно расширенного канала составляет 16 и
КПД МАП снижается до 25%. Однако, если параметр пост-расширения
установлено значение 4, каждый конвейер свертки атомного цикла будет извлекать 4 соседних
линии и объедините их в строку C = 64.Затем эффективность MAC возвращается к
100%.
Однако, если параметр пост-расширения
установлено значение 4, каждый конвейер свертки атомного цикла будет извлекать 4 соседних
линии и объедините их в строку C = 64.Затем эффективность MAC возвращается к
100%.
Некоторое ограничение пост-расширения канала:
Пост-расширение канала предназначено только для свертки входного изображения.
Пост-расширение канала поддерживает только расширение на 2 строки и расширение на 4 строки.
Пост-расширение канала ограничено размером предварительно расширенного канала и свертка x шаг
Канал дополнительный номер | conv_x_stride limit | предварительно расширенный канал ограничение размера |
|---|---|---|
1-строчный | № | № |
2-строчный | (conv_x_stride * ori_channel_size) <= 32 | <= 32 |
4 линии | (conv_x_stride * ori_channel_size) <= 16 | <= 16 |
Необходимо отметить, что номер канала после расширения (N)
не должно быть меньше высоты ядра (R). Оборудование может
автоматически настраивать избыточные линии, чтобы избежать их вовлечения в
вычисление. Однако это также означает, что пользователю не следует ожидать, что N раз
улучшения эффективности MAC для этого случая.
Оборудование может
автоматически настраивать избыточные линии, чтобы избежать их вовлечения в
вычисление. Однако это также означает, что пользователю не следует ожидать, что N раз
улучшения эффективности MAC для этого случая.
Многопакетный режим
ЯдроNVDLA также поддерживает многопакетную обработку для повышения производительности и уменьшить пропускную способность, особенно для уровней с полным подключением (FC). В выходом одного уровня FC является куб данных 1x1xC. Это означает, что все веса в один слой FC используется только один раз. Одна операция полосы на уровне FC имеет только одна атомарная операция.Но конвейеру свертки требуется 16 циклов, чтобы вес загрузки для следующей атомарной операции. Это вводит много пузырей в КПД трубопровода и МАП снижается до 6,25%. Чтобы сохранить эффективность, механизм NVDLA может применять многопакетный режим.
Мультипакет — это специальная опция для режима постоянного тока с несколькими входами.
кубы данных объектов обрабатываются сразу. Конволюционный конвейер
получит несколько входных данных
кубики для одного набора весовых ядер. Это также меняет атомарный
операция. Загружаются маленькие кубики из разных кубов входных данных
чередуются для атомарной операции один за другим.Полосовая операция
затем содержит атомарные операции для нескольких пакетов. Поскольку веса используются повторно
через полосу весов циклы загрузки скрываются, и эффективность увеличивается.
Конволюционный конвейер
получит несколько входных данных
кубики для одного набора весовых ядер. Это также меняет атомарный
операция. Загружаются маленькие кубики из разных кубов входных данных
чередуются для атомарной операции один за другим.Полосовая операция
затем содержит атомарные операции для нескольких пакетов. Поскольку веса используются повторно
через полосу весов циклы загрузки скрываются, и эффективность увеличивается.
Длина полосовой операции с разным размером партии:
Размер партии | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
Нормальная длина | 16 | 8×2 | 8×3 | 4×4 | 4×5 | 4×6 |
Макс. | 32 | 16×2 | 16×3 | 8×4 | 8×5 | 8×6 |
Размер партии | 7 | 8 | 9 | 10 | 11 | 12 |
Нормальная длина | 4×7 | 2×8 | 2×9 | 2×10 | 2×11 | 2х12 |
Макс.длина | 8×7 | 4×8 | 4×9 | 4×10 | 4×11 | 4×12 |
Размер партии | 13 | 14 | 15 | 16 ~ 32 | ||
Нормальная длина | 2×13 | 2×14 | 2×15 | 1xN | ||
Макс. | 4×13 | 4×14 | 4×15 | 1xN |
 длина
длина длина
длинаРис.51 Многоканальный режим
Расширение
Расширение — это опция, которая увеличивает ядро в размерах R и S. с нулевыми значениями. При необходимости эту функцию можно включить с помощью ПО.
На диаграмме ниже показан случай с параметром дилатации = 3.
Рис.52 Увеличение веса
NVDLA поддерживает расширение как в R, так и в S.
Пределы расширения:
Рассмотрение мощности
Конвейер сверткиподдерживает синхронизацию для каждой основной стадии конвейера.Если стадия конвейера простаивает и нет действующего HW-уровня, путь к данным этапа трубопровода будет закрытым.
Свертка DMA
Обзор
Convolution DMA (CDMA) — это этап конвейера в конвейере свертки. Это
извлекает данные из SRAM / DRAM для операции свертки и сохраняет их
в буфер (буфер свертки или CBUF) в порядке, необходимом для
сверточный двигатель. Поддерживаемые форматы ввода:
Поддерживаемые форматы ввода:
Два канала чтения подключаются от CDMA к интерфейсу AXI.Эти канал чтения веса и канал чтения данных. Чтобы получить форматы ввода перечисленные выше каналы настроены для этого формата. Таблица ниже записывается формат входных данных для чтения сопоставления каналов.
Ввод Формат | Кейс для изображений | без сжатия Характерная черта Корпус | без сжатия Вес кейса | сжатый Вес кейса |
|---|---|---|---|---|
Данные пикселей | данные канал | NA | NA | NA |
без сжатия характерная черта данные | NA | данные канал | NA | NA |
без сжатия вес | NA | NA | вес канал | NA |
Редкий сжатый вес | NA | NA | NA | вес канал |
WMB | NA | NA | NA | вес канал |
WGS | NA | NA | NA | вес канал |
Convolution DMA отправляет только запросы чтения из памяти. Все запросы на чтение памяти, отправленные
DMA свертки выровнены по 64 байта.
Все запросы на чтение памяти, отправленные
DMA свертки выровнены по 64 байта.
Рис.53 Свертка DMA
CDMA состоит из трех субмодулей для выборка пиксельных данных или данных характеристик для свертки: CDMA_DC, CDMA_WG и CDMA_IMG. Процедуры эти субмодули похожи, но различаются порядком данных в ОЗУ CBUF. В любой момент только один из субмодулей активируется для получения данных о пикселях / функциях.
Возьмем CDMA_DC в качестве примера, чтобы представить процедуры:
Проверить состояние буфера свертки на предмет наличия достаточного свободного места.
Создание транзакций чтения
Кэширование данных функций в общих буферах
Изменить форму кубов элементов в правильном порядке
Сгенерировать адрес записи буфера свертки
Записать данные признаков в буфер свертки
Обновление состояния буфера свертки в субмодуле CDMA_STATUS
Convolution DMA использует специальный механизм для обработки
требования Винограда. CDMA_WG имеет очень похожую структуру и
функциональность CDMA_DC. Однако в результате данные функции
организация в свертке
буфер другой. Таким образом, CDMA_WG имеет особую последовательность выборки.
Кроме того, CDMA_WG всегда выполняет расширение канала Винограда.
CDMA_WG имеет очень похожую структуру и
функциональность CDMA_DC. Однако в результате данные функции
организация в свертке
буфер другой. Таким образом, CDMA_WG имеет особую последовательность выборки.
Кроме того, CDMA_WG всегда выполняет расширение канала Винограда.
Механизм CDMA_IMG извлекает данные пикселей из внешней памяти. Это генерирует адрес в соответствии с форматом данных, меняет порядок пикселей элементы, и записывает их в соответствующую запись свертки буфер. Базовое поведение CDMA_IMG похоже на CDMA_DC, но работает с пиксельными данными.
Только механизм CDMA_DC поддерживает многопакетный режим. То есть получить больше более одного куба входных данных объекта в одном HW-слое для улучшения спектакль. Максимальный размер партии может быть до 32.
CDMA также использует специальный механизм для выборки веса: CDMA_WT.
CDMA_WT прост по сравнению с другими механизмами DMA, за исключением
что он может поддерживать три потока чтения одновременно. Если входной вес
формат не сжат, он только извлекает данные о весе. Если входной вес
формат сжат, выбираются вес, WMB и WGS.Пожалуйста, см. Форматы данных для получения более подробной информации о форматах веса.
Если входной вес
формат сжат, выбираются вес, WMB и WGS.Пожалуйста, см. Форматы данных для получения более подробной информации о форматах веса.
Если входные данные веса сжаты, два арбитра включены для порядок чтения потоков. Сначала арбитр взвешенного кругового алгоритма предоставляет запрос из потока весов или потока WMB. Затем победитель соревнуется с WGS запрашивает пар со статическим приоритетом арбитража. WGS всегда имеет приоритет. Последний выигрышный запрос отправляется в канал взвешивания для выборки данных.
CDMA_WT всегда пытается заполнить буфер свертки как можно больше, до тех пор, пока не закончатся бесплатные записи или не будет завершена выборка веса.
CDMA поддерживает и передает состояние как весового буфера, так и входа
буфер данных в CBUF. Есть две копии статуса в CDMA и CSC. Два
модули обмениваются информацией об обновлении / выпуске, чтобы решить, когда получить
данные о новой функции / пикселях / весе и когда выпускать эти элементы данных.
Рассмотрение мощности
Convolution DMA применяет синхронизацию в тракте данных. Часы пути данных свертка DMA стробируется, когда она простаивает и аппаратный уровень не настраивается в программируемых регистрах.Подмодуль regfile внутри свертка DMA не является синхронизируемой, поэтому можно программировать новые команды.
Накопитель свертки
Обзор
Накопитель свертки (CACC) — это этап конвейера свертки. после CMAC. Он используется для накопления частичных сумм из MAC свертки и округлить / насыщать результат перед отправкой в SDP. Кроме того, большой буфер в накопителе свертки может сглаживать пиковую пропускную способность конвейера свертки.
Конечный результат аккумулятора в CACC — 48 бит для INT16 и 34 бита для INT8.
Разрядность между CACC и SDP равна 32.
Для точности INT8 и INT16 перед отправкой результата в SDP выполняется операция округления и насыщения.
Точность округления настраивается полем CLIP_TRUNCATE в регистре D_CLIP_CFG. Для FP16 значение просто конвертируется из FP48 в FP32.
Для FP16 значение просто конвертируется из FP48 в FP32.
Компоненты в CACC включают группу SRAM сборки, группу SRAM доставки, массив сумматора, массив усечения, контроллер действительного кредита и средство проверки.
Вот рабочий поток CACC:
Предварительная выборка накопительных сумм из группы SRAM сборки.
При поступлении частичных сумм отправить их в массив сумматоров вместе с накопительные суммы. Если частичные суммы взяты из первой полосы операции накопительные суммы должны быть 0.
Получить новые накопительные суммы с выходной стороны сумматора.
Сохранить в сборку Группа SRAM
Повторите шаги 1 ~ 3 для работы с полосой, пока канал операция сделана.
Если операция с каналом выполнена, выходной сигнал сумматоров округляется и насыщается.
Соберите результаты предыдущего шага и сохраните их в группе SRAM доставки.
Загрузить результаты из группы буферов доставки и отправить их в SDP
Рис. 57 Аккумулятор свертки
57 Аккумулятор свертки
Группа SRAM сборки содержит 4 SRAM 96Bx32 и 4 SRAM 64Bx32. В Группа буферов используется для кэширования накопительных сумм с высокой точностью.За прямая свертка, сборочная группа SRAM действует как один буфер 96Bx128 для int16 / fp16 или один буфер 136Bx128 для int8. Для свертки Винограда SRAM сборки действует как один буфер 384Bx32 для int16 / fp16 или один 544Bx32 буфер для int8. Для создания круга чтения и сохранения требуется не менее 11 циклов. для монтажной группы.
Группа доставки SRAM содержит 8 SRAM 64Bx32. Буферная группа используется для кэширования результата, который будет доставлен в SDP. Вход варьируется от 16 до 128 элементов за цикл, при этом вывод всегда 16 элементов за цикл.
Точность накопительной суммы указана ниже.
Формат ввода | Накопительная сумма | Усеченный результат |
|---|---|---|
INT8 | ИНТ34 | ИНТ32 |
INT16 | ИНТ48 | ИНТ32 |
FP16 | FP44 (показатель степени 8b, 38b десятичное со знаком) | FP32 (IEEE754 стандарт) |
В сумматоре имеется 64 сумматора INT48, 64 сумматора INT34 и 64 сумматора FP48. сумматоры.Часть из них активированы в другом режиме
сумматоры.Часть из них активированы в другом режиме
Формат ввода и режим | Активировано INT48 Сумматоры | Активировано INT34 Сумматоры | Активированный FP44 Сумматоры |
|---|---|---|---|
INT8 DC / изображение | Сумматор 0 ~ 15 | Сумматор 0 ~ 15 | NA |
INT8 Виноград | Сумматор 0 ~ 63 | Сумматор 0 ~ 63 | NA |
INT16 DC / изображение | Сумматор 0 ~ 15 | NA | NA |
INT16 Виноград | Сумматор 0 ~ 63 | NA | NA |
FP16 DC / Изображение | NA | NA | Сумматор 0 ~ 15 |
FP16 Виноград | NA | NA | Сумматор 0 ~ 63 |
Для поддержки многопакетной опции в режиме постоянного тока CACC применяет переназначение данных
функция в группе доставки SRAM. Это означает, что когда включена многопакетная обработка,
порядок данных в группе SRAM доставки может не соответствовать последовательности из
сборочная группа SRAM. Пишем контроллер доставки SRAM объединим
атомные кубы, если они будут в одном 64-байтовом пакете после дальнейшего
расчет в SDP. Эта функция позволяет SDP отправлять 64-битную выровненную запись
запрашивает как можно больше при включенной мульти-пакетной обработке. Ниже диаграмма
показан случай с размером партии 2.
Это означает, что когда включена многопакетная обработка,
порядок данных в группе SRAM доставки может не соответствовать последовательности из
сборочная группа SRAM. Пишем контроллер доставки SRAM объединим
атомные кубы, если они будут в одном 64-байтовом пакете после дальнейшего
расчет в SDP. Эта функция позволяет SDP отправлять 64-битную выровненную запись
запрашивает как можно больше при включенной мульти-пакетной обработке. Ниже диаграмма
показан случай с размером партии 2.
Рис.58 Переназначение данных в CACC
Протокол между CMAC и CACC является протоколом только действительного типа.В случае переполнение, CACC использует протокол действительного кредита для противодействия CSC.
Рассмотрение мощности
Накопитель свертки применяет синхронизацию в тракте данных.
Часы данных
Путь к аккумулятору свертки закрывается, когда он простаивает и нет
HW-слой доступен из программируемых регистров.
Программируемые регистры в CACC не синхронизируются, чтобы позволить
для программирования новых инструкций.
Одноточечный процессор данных
Обзор
Одноточечный процессор данных (SDP) выполняет постобработку операции на уровне отдельных элементов данных.В версии NVDLA 1.0 обработка точек предназначена для выполнения следующих операций.
Добавление смещения
Для сверточного слоя всегда есть добавление смещения после свертки. В NVDLA мы добавляем смещение в SDP.
Математическая формула для сложения смещения:
\ [y = x + bias \]
x — входные данные могут поступать из конвейера свертки или SDP. M-RDMA;
Смещение— это предварительно обученный параметр, который может быть одним из трех вариантов:
Регистр: Если смещение уникально для всего куба данных;
SDP B / N / E-RDMA для поканального режима: если смещение разделяется для всех элементов в том же канале;
SDP B / N / E-RDMA для каждого элемента, режим: если смещение другое поэлементно;
Нелинейная функция
Аппаратное обеспечение нелинейной функции в SDP используется для выполнения активации
слойные операции. {- Икс}}\).
{- Икс}}\).
Рис.59 Сигмоидная функция
Рис. 60 Функция гиперболического тангенса
В случае активации функции ReLU она может быть реализована напрямую аппаратно. логика. Сигмоидальная и гиперболическая касательная функции равны нелинейные функции, поэтому ожидается, что они будут реализованы через поиск таблица, которую можно загрузить функцией по мере необходимости. (см. раздел «Программирование LUT» документа «Руководство по программированию»).
Пакетная нормализация
Пакетная нормализация — широко используемый слой.{‘} = \ frac {x — \ mu} {\ theta} \]
Где \ (\ mu \) — среднее значение, \ (\ theta \) — стандартная дисперсия, а x — элемент кубы данных функций.
SDP поддерживает пакетную нормализацию с заданным средним / стандартным отклонением параметры. Параметры получены в процессе обучения.
SDP может поддерживать параметр уровня или параметр канала для пакетной обработки
нормализация операции. Когда параметр для каждого канала, они
чередуются в памяти (см. Форматы данных).
И DMA в SDP получит
параметр и вычислить куб данных признаков из конвейера свертки.
Когда параметр для каждого канала, они
чередуются в памяти (см. Форматы данных).
И DMA в SDP получит
параметр и вычислить куб данных признаков из конвейера свертки.
Элементный слой
Слой Element-Wise относится к типу операции между двумя объектами. кубы данных с одинаковым размером W, H и C. Эти два Ш x В x С кубы данных функций выполняют поэлементное сложение, умножение или макс / мин операции сравнения и вывести один куб данных функции Ш x В x C.
Рис.61 Поэлементное управление
Модуль SDP может поддерживать поэлементные уровни для всех 3 типов данных. точность. Каждый поэлементный уровень в SDP настроен для добавления или умножение.
SDP поддерживает как онлайн-режим, так и автономный режим для поэлементного слоя. В онлайн-режиме один куб данных поступает из конвейера свертки, а другой куб входных данных извлекается из памяти. В автономном режиме SDP извлекает оба куба входных данных из памяти.
PReLU
В отличие от ReLU, который обрезает отрицательные значения до 0, PReLU действует как:
Фиг. 62 PReLU
62 PReLU
Коэффициент масштабирования k может быть либо константой куба, либо каналом. вариант.
SDP поддерживает его, обновляя поведение множителя: если режим PReLU выбрано, множитель пропустит положительное значение и применит масштабирование к только отрицательные значения.Режим PReLU поддерживается множителем во всех 3-х подмодули.
Обратите внимание:
1. Функции BatchNorm и PReLU являются эксклюзивными для определенного субблока, это связано с тем, что для субъединицы доступен только один множитель;
2. Если PReLU включен для одного субблока, ALU в этом блоке ДОЛЖЕН быть обошел. Это связано с тем, что есть только одно усечение для субблока и отрицательный / положительный здесь требует другого усечения.
Преобразование формата
NVDLA поддерживает точность INT8, INT16 и FP16.Чем ниже точность, тем выше производительность, в то время как более высокая точность обеспечивает лучшие результаты вывода.
Возможно, программное обеспечение требует разной точности для разных
аппаратные уровни, поэтому необходимо прецизионное преобразование.
SDP отвечает за прецизионное преобразование. Поддерживаемые преобразования на одном уровне оборудования перечислены в Таблице 30, «Преобразование точности для Слой SDP (офлайн) ». Если SDP получает данные из ядра свертки, поддерживаемое преобразование формата указано в Таблице 29.
Преобразование точности и нормальная функция SDP независимы, что означает, что SDP может выполнять преобразование и работу (например: добавление смещения, BatchNorm, EW и т. Д.) Одновременно.
Сравнение
Режим сравнения в SDP_Y принимает 2 входа, а затем сравнивает их. Если любая пара элементов из кубики входных данных не совпадают, регистр состояния обновляется после аппаратного уровня завершено.
Для экономии полосы пропускания не будет никакой записи вывода на внешний память в режиме сравнения.
Описание функции
На следующей схеме показаны внутренние блоки субблока точечной обработки и подключения к другим подразделениям.
Рис. 63 Блок-схема одноточечной обработки данных
63 Блок-схема одноточечной обработки данных
Функциональные блоки:
Есть несколько функциональных блоков, каждый из которых предназначен для разных назначение:
Блок M используется для выбора входных данных из MEM или Conv Core, которые могут быть набор из регистра
Блок X1 / X2 имеет ту же архитектуру и поддерживает: добавление смещения, BatchNorm, PReLU, ReLU, Eltwise.
Блок Y в первую очередь предназначен для поэлементной работы, но он также может поддержка смещения сложения, PReLU. Дополнительная операция LUT, которую можно выбрать перед выводом для выполнения любой нелинейной операции.
Блок C1 / C2 предназначен для дополнительного масштабирования и смещения для экономии битов, пока сохраняя высокую точность.
Демультиплексор на самом конце для отправки выходных данных в любой WDMA для запись обратно в память или в PDP для последующей операции объединения.
Большинство функциональных блоков имеют настраиваемый режим байпаса, поэтому ПО может
выберите полную или частичную функцию, чтобы соответствовать всем операциям, необходимым в
один аппаратный слой.
Пропускная способность каждого субблока:
Подраздел | Пропускная способность |
|---|---|
X1 / X2 | 16 элементов / цикл |
Y | 4 элемента / цикл |
Рабочий режим: Летающий:
На лету: исходные данные взяты из Conv-Core
Off-fly: исходные данные из памяти, которая считывается M-RDMA
Дополнение смещения:
Данные операндов могут быть на каждый элемент, на канал или на куб, фактическая операция может выполняться в любом из X1 / X2 / Y в зависимости от конфигурация программного обеспечения
Данные смещения будут извлечены из MEM для каждого элемента / канала.Если усечение включено, все элементы имеют одно и то же значение усечения
Данные смещения будут установлены регистром, если на куб
Множитель будет обойден
Нормализация партии
Данные операндов могут быть на каждый элемент, на канал или на куб, фактическая операция может выполняться в X1 / X2 / Y на основе программного обеспечения конфигурация.

Данные операнда будут извлечены из MEM для каждого элемента / канала.Если усечение включено, все элементы используют одно и то же усечение значение.
Данные операнда будут установлены через конфигурацию программного обеспечения зарегистрируйте, если на куб.
Данные операндов для сумматора и умножителя должны быть упакованы вместе и в том же формате для каждого элемента, для каждого канала или для куб. Подробнее см. Форматы данных.
ReLU можно отключить или включить.
Element-Wise
Данные операндов могут быть на каждый элемент, на канал или на куб
Данные операнда будут извлечены из MEM, если для каждого элемента / канала, если усечение включено, все элементы используют одно и то же усечение значение
Данные операнда будут установлены регистром конфигурации программного обеспечения, если на куб
Данные операнда должны быть либо для max / min / sum, либо для множителя
LUT можно обойти или включить
PReLU:
Данные операнда могут быть на канал или на куб
Данные операнда будут извлечены из MEM, если на канал, если усечение включено, все элементы имеют одно и то же значение усечения
Данные операнда будут заданы регистром, если на куб;
Бит режима PReLU должен быть установлен как истинный для умножителя.
 {‘} — \ mu} {\ theta} \).
{‘} — \ mu} {\ theta} \).Если мы объединим эти две формулы в одну: \ (y = \ frac {x + bias — \ mu} {\ theta} = \ frac {x — (\ mu — bias)} {\ theta} \).
Поскольку \ (\ mu, \ theta, bias \) являются предварительно обученными параметрами, программное обеспечение может объединить их в один куб. таким образом, это выполнимо;
Вкратце, функции, поддерживаемые каждым субблоком, перечислены в таблица ниже:
Таблица 51 Поддерживаемые сценарии использования SDP Модуль
Х1
Х2
Y
Добавление смещения
Y
Y
Y
BatchNorm
Y
Y
Y
Элтвайз
Y
Y
Y
PReLU
Y
Y
Y
ReLU
Y
Y
Y
Нелинейная активация
№
№
Y
Последовательность данных:
Возьмем для примера сложение смещения смещения (BIAS).
 Если смещение / операнд данные для каждого элемента:
Если смещение / операнд данные для каждого элемента:Последовательность ввода / вывода точечной обработки определяется сверткой выходная последовательность.В большинстве случаев порядки входной и выходной последовательности в все интерфейсы ввода / вывода одинаковы, и это точно последовательность вывода свертки, которая показана на следующей диаграмме.
Рис.64 Последовательности ввода / вывода точечной обработки
Данные смещения / операнда на канал:
Данные будут извлечены из памяти и поддерживать одно значение для нескольких циклы, когда данные объекта обрабатываются на одной и той же поверхности. Тогда это будет обновить до значения следующей поверхности, когда данные объекта изменятся на следующую поверхность.
Данные смещения / операнда на куб:
Данные будут установлены в регистре конфигурации программного обеспечения и не изменятся. на протяжении всего времени выполнения для аппаратного уровня.
Оценка размера буфера
В единственном субблоке обработки данных есть три основных буфера: LUT в блок активации, чтение буфера DMA и запись буфера DMA.
 LUT размер
(65+ 257) * 2 (BPE) = 644 байта.
LUT размер
(65+ 257) * 2 (BPE) = 644 байта.Для буфера DMA чтения функции в блоке M есть два ограничения: рассмотреть, чтобы определить его размер.Один касается задержки доступа к внутренней SRAM. Ожидается, что задержка составит около 128 циклов. Другой — пропускная способность доступа. Каждый элемент данных частичной функции составляет 16 бит, и SDP должен обрабатывать 16 элементов на цикл, поэтому необходимая полоса пропускания составляет 32 байта. Чтение Таким образом, размер буфера DMA равен \ (128 \ times 32 = 4 \ KB \).
Данные функции Unlinke, если BS / BN / EW должны поддерживать режим BatchNorm который имеет 32 бита на элемент. Таким образом, размер буфера чтения DMA для этих 2 модули: 32 (бит) * 128 (циклы) * 16 (элементы) / 8 = 8 Кбайт.
Рассмотрение мощности
ОперацииElement-Wise / BatchNorm не всегда включены в данную сеть. Таким образом, для некоторых операций BS / BN / EW не работают полностью, поэтому часы стробирование используется.

Планарный процессор данных
Обзор
Планарный процессор данных (PDP) выполняет операции по ширине x высота плоскости. В версии 1.0 NVDLA PDPD предназначен для выполнить объединение слоев. Максимальное, минимальное и среднее объединение поддерживаются методы.Несколько соседних элементов ввода внутри плоскости будет отправлено нелинейной функции для вычисления одного выходного элемента. На следующей диаграмме показан пример максимального пула. Максимальное значение среди 3×2 соседних элементов находится значение результата объединения.
Рис.65 Пример максимального объединения
На следующей схеме показаны внутренние блоки субблока PDP, наряду с подключениями к другим подразделениям и подразделениям. Диаграмма концептуально фиксирует функциональность и не показывает актуальные RTL-модули и иерархии.Планарные данные подблок обработки принимает данные из SDP или MCIF / SRAMIF и отправляет данные в MCIF / SRAMIF.
Рис.66 Блок-схема планарной обработки
Рис.
 67 Процесс обработки в одной плоскости
67 Процесс обработки в одной плоскостиОперации объединения выполняются в пределах плоскости. Нет никаких помех между разными самолетами. На рис.68 представлена полная схема объединение в одну плоскость. Смещение двух соседних ядер называется шаг. Когда шаг ядра меньше R и S ядра, перекрывающиеся линии.Некоторая линия может использоваться более чем двумя соседними ядра. Входные данные передаются в потоке в порядке растрового сканирования. Для каждого пула ядро обрабатываемые данные также передаются в потоковом режиме в порядке растрового сканирования.
Если элемент входных данных является первым элементом ядра, он будет хранится в буфере линии общего доступа. Данные в буфере линии общего доступа относятся к как частичный результат. Если элемент входных данных не является первым элементом ни последний элемент ядра, он не будет работать с существующими частичный результат из общего буфера, и результат будет сохранен в та же запись исходного частичного результата.
 Расчет частичного результата
выполняется в блоке предварительной обработки.
Расчет частичного результата
выполняется в блоке предварительной обработки.В случае схем объединения макс / мин частичным результатом является максимальное / минимальное значение входного элемента и исходного частичного результат.
В случае схемы объединения средних значений частичным результатом является сумма элемент ввода и исходный частичный результат.
Если элемент входных данных является последним элементом ядра, он будет работает с существующим частичным результатом из буфера линии общего доступа к генерировать предварительный результат.Блок постобработки получит предварительный финал результат из буфера линии общего доступа, и после правильных операций он генерирует конечный результат. Этот окончательный результат отправляется в SRAMIF или MCIF.
В случае схем объединения макс / мин предварительным результатом является конечный результат, никаких дополнительных операций не требуется.
В случае схемы среднего пула окончательный результат может быть рассчитан по \ (pre \ _ final \ _ result \ times \ frac {1} {\ text {Kerne} l _ {\ text {width}} \ times Kernel _ {\ text {height}}} = pre \ _ final \ _ result \ масштаб \ _ коэффициент \ _ ширина \ масштаб \ _ коэффициент \ _ высота \).Деление дорого для аппаратной реализации, поэтому пара \ (масштаб \ _ коэффициенты \) используются для преобразования деления в умножение.
Наибольшее количество ядер, которые совместно используют одну строку данных: определяется по \ (\ text {потолок} \ left (\ frac {Kernel \ _ Height} {Stride \ _ H} \ right) \). Общее количество входов в буфер, необходимое в плоскости составляет \ (ширина \ _ out \ times потолок \ left (\ frac {Kernel \ _ Height} {Stride \ _ H} \ right) \) , а в дизайне RTL назначенный общий номер записи буфера \ (total \ _ buf \ _ entry \) в одной плоскости, как показано ниже, и 112 бит за каждую запись:
если \ (\ text {потолок} \ left (\ frac {Kernel \ _ Height} {Stride \ _ H} \ right) \) = 1, \ (всего \ _ buf \ _ entry \) = 16 * 4 * 8 = 512;
если \ (\ text {потолок} \ left (\ frac {Kernel \ _ Height} {Stride \ _ H} \ right) \) = 2, \ (всего \ _ buf \ _ entry \) = 16 * 4 * 4 = 256;
если \ (\ text {потолок} \ left (\ frac {Kernel \ _ Height} {Stride \ _ H} \ right) \) = 3 или 4, \ (total \ _ buf \ _ entry \) = 16 * 4 * 2 = 128;
если \ (\ text {потолок} \ left (\ frac {Kernel \ _ Height} {Stride \ _ H} \ right) \) > 4, \ (всего \ _ buf \ _ entry \) = 16 * 4 * 1 = 64;
Поскольку операция объединения является методом понижающей выборки, существует значительный объем информации отбрасывается.Объединение в большой ядро слишком разрушительное. В текущих анализируемых сетях есть три наиболее распространенных случая, один — размер пула 3×3, с шаг 2×2. Другой — объединение размер 2х2, с шагом 2х2, а последняя размер пула 3×3, с шагом 1×1. Есть два других менее используемых случая: один — объединение размер 3×3, с шагом 3×3. И другие размер пула 7×7, с шагом 1×1.
Таблица 52 Сводка типов ядра пула Сеть
Итого Объединение Слой Число
размер 3×3 шагать 2×2 Число
размер 2х2 шагать 2×2 Число
размер 3×3 шагать 1×1 Число
Другое Слой Число
Другое Слой Объединение Формат
AlexNet
3
3
0
0
0
NA
Overfea т-Accur съел
3
0
1
0
2
размер 3×3 шагать 3×3
VGG 19
5
0
5
0
0
NA
GoogLeN et
14
4
0
9
1
размер 7×7 шагать 1х1
NVDrive Нетто @ 960 х540
12
3
0
9
0
NA
Таким образом, диапазон размера ядра пула 2 ~ 8 (как по ширине, так и по высоте) и 1 ~ 8 шага достаточно для нормального использования.В дизайне RTL мы устанавливаем объединение диапазона размеров ядра от 1 до 8 и установка диапазона шага от 1 до 16.
Есть два входных тракта для субблока обработки планарных данных. Один подблок обработки одноточечных данных, а другой — внешняя RAM (MC / SRAM). Есть один путь выходных данных для планарной обработки подразделение. Выходные данные всегда отправляются в ОЗУ вне PDP (MC / SRAM). В обычная практика, слой пула вставляется после сверточного слой. Чтобы сэкономить потребление памяти при доступе к памяти, планарная обработка данных субблок должен напрямую получать данные от точечного блока обработки, если выполняется следующее условие.Предположим, что ширина вывода равна \ (\ text {Ширина} _ {\ text {output}} \), общий размер буфера в байтах равен \ (\ text {Size} _ {\ text {buffer}} \), номер перекрывающейся строки \ (\ text {Num} _ {overlapped \ _ line} \), ширина данных в байтах равна \ (\ text {Data} _ {\ text {width}} \), номер пространственной плоскости называется текущим номером канала \ (\ text {Num} _ {текущие \ _ каналы} \), обычно \ (\ text {Num} _ {текущие \ _ каналы} \) должно быть равно kernel_per_group (16 для INT16 / FP16, 32 для канала INT8). Ниже планарная обработка в оперативном режиме работы.
\ [Ширина_ {вывод} \ leq \ frac {{Размер} _ {{буфер}}} {{Данные} _ {{ширина}} \ times {Num} _ {текущие \ _ каналы} \ times {Num} _ { overlapped \ _ line}} = \ frac {{Size} _ {{buffer}}} {{Data} _ {{width}} \ times {Num} _ {текущие \ _ каналы} \ times f (ceil \ left ( \ frac {{Высота} _ {{poolin} g _ {{kernel}}}} {{Strid} e_ {h}} \ right))} \]
Если \ (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}} {\ text {Strid} e_ {h}} \ right) = 1 \) , \ (f \ left (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}}} {\ text {Strid} e_ {h}}) \ вправо) \ вправо) = 1 \)
Если \ (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}} {\ text {Strid} e_ {h}} \ right) = 2 \) , \ (f \ left (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}}} {\ text {Strid} e_ {h}}) \ право) \ право) = 2 \)
Если \ (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}} {\ text {Strid} e_ {h}} \ right) = 3 \ или \ 4 \) , \ (f \ left (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}}} {\ text {Strid} e_ {h}}) \ вправо) \ вправо) = 4 \)
Если \ (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}} {\ text {Strid} e_ {h}} \ right)> 4 \) , \ (f \ left (\ text {ceil} \ left (\ frac {\ text {Height} _ {\ text {poolin} g _ {\ text {kernel}}}}} {\ text {Strid} e_ {h}}) \ вправо) \ вправо) = 8 \)
Когда входные данные поступают из подмодуля точечной обработки, последовательность входных данных является то же, что и выходные последовательности свертки, которые показаны ниже диаграмма.
Рис.68 Входная последовательность планарной обработки, режим 0
Выходная последовательность показана на следующей диаграмме.
Рис.69 Выходная последовательность планарной обработки, режим 0
Если условие работы плоской обработки на лету не выполняется, планарная обработка должна работать на лету режиме он принимает данные из PDMA, а текущий номер канала всегда 16. Есть два подслучая: один — без разделения по ширине, а второй — другое — разделенное по ширине. Последовательность входных данных показана на следующей диаграмме.
Рис.70 Входная последовательность планарной обработки, режим 1 и 2
Последовательность выходных данных показана на следующей диаграмме.
Рис.71 Выходная последовательность планарной обработки, режимы 1 и 2
Режим работы
Источник данных
Раздельная ширина
Режим 0
Одноточечная обработка данных
№
Режим 1
MC / SRAM
№
Режим 2
MC / SRAM
Есть
Оценка размера буфера
В блоке обработки планарных данных есть три основных буфера: общий строчный буфер, чтение буфера DMA и запись буфера DMA.Для линии акций буфер, его размер определяет, может ли PDP работать непосредственно с данными из SDP или нет. На основе куба входных данных высота \ (\ text {Высота} _ {\ text {куб входных данных}} \), ядро пула высота \ (\ text {Высота} _ {\ text {ядро пула}} \), ядро пула шаг в высоту direction \ (\ text {stride} _ {\ text {pooling kernel}} \), выходные данные ширина куба \ (\ text {Ширина} _ {\ text {куб выходных данных}} \), размер группы (16 элементов int16 / FP16 или 32 элемента int8, ~ 32 byte) \ (\ \ text {Group} _ {\ text {size}} \) и bytes_per_element (14/8 для INT8, 28/8 для INT16, 28/8 для FP16).
\ [Buffer \ Size = \ text {Ширина} _ {\ text {куб выходных данных}} * \ frac {\ text {Height} _ {\ text {ядро объединения}}} {\ text {stride} _ {\ text {объединение ядра}}} * \ text {Group} _ {\ text {size}} * байтов \ _ на \ _ элемент \]
Если емкость буфера линии совместного использования меньше требуемого размера потребления, PDP должны работать в автономном режиме, поэтому будет падение производительности, так как дополнительное время необходимо для сохранения данных в MC / SRAM, а затем для возврата в PDP для обработки пула.
Таблица 53 Сводка по потреблению буфера линии пула долей Слой
Канал Число
Ядро Размер
Ядро Шаг
Выход Ширина
Минимум Размер
Максимум Размер
AlexNet — бассейн1
96
3
2
27
1728
5184
AlexNet — бассейн2
128
3
2
13
832
3328
AlexNet — бассейн5
128
3
2
6
384
1536
Overfea т-Accur ели — слой 3
96
3
3
36
1152
6912
Overfea т-Accur ели — слой 6
256
2
2
15
480
7680
Overfea т-Accur ели — слой 19
1024
3
3
5
160
10240
VGG 19 — бассейн1
64
2
2
112
3584
14336
VGG 19 — бассейн2
128
2
2
56
1792
14336
VGG 19 — бассейн3
256
2
2
28
896
14336
VGG 19 — бассейн4
512
2
2
14
448
14336
VGG 19 — бассейн5
512
2
2
7
224
7168
GoogLeN et — бассейн1 / 3 x3_s2
64
3
2
56
3584
7168
GoogLeN et — бассейн2 / 3 x3_s2
192
3
2
56
3584
21504
GoogLeN et — восприимчивый on_3a / p оол
192
3
1
28
2688
32256
GoogLeN et — восприимчивый on_3b / p оол
256
3
1
28
2688
43008
GoogLeN et — бассейн3 / 3 x3_s2
480
3
2
14
896
13440
GoogLeN et — восприимчивый on_4a / p оол
480
3
1
14
1344
40320
GoogLeN et — восприимчивый on_4b / p оол
512
3
1
14
1344
43008
GoogLeN et — восприимчивый on_4c / p оол
512
3
1
14
1344
43008
GoogLeN et — восприимчивый on_4d / p оол
512
3
1
14
1344
43008
GoogLeN et — восприимчивый on_4e / p оол
528
3
1
14
1344
44352
GoogLeN et — бассейн4 / 3 x3_s2
832
3
2
7
448
11648
GoogLeN et — восприимчивый on_5a / p оол
832
3
1
7
672
34944
GoogLeN et — восприимчивый on_5b / p оол
832
3
1
7
672
34944
GoogLeN et — бассейн5 / 7 x7_s1
1024
7
1
1
224
14336
В приведенной выше таблице большинство минимальные случаи — менее 7 Кбайт.Итак, в результате балансировки производительность и размер буфера разделяемой линии установлен как 7 Кбайт.
Для чтения буфера DMA существует два ограничения для определения его размера. Один касается задержки доступа MC, которая, как предполагается, составляет 128 циклы. Другой — пропускная способность доступа. Случай максимальной производительности — 8 Байт на цикл (8 элементов в int8, 4 элемента в int16 / fp16). Итак, прочтите Размер буфера DMA равен \ (128 \ times 8 = 1 Кбайт \).
Рассмотрение мощности
Цели подблока планарной обработки для уровня объединения в NVDLA 1.0, на основе при анализе текущих сетей использование планарной обработки не ожидается высокий.
Таблица 54 Сводная информация о процентном содержании уровня пула Сеть
Всего пулов Номер слоя
Общий слой Номер *
В процентах
AlexNet
3
13
23%
Превышение точности
3
12
25%
VGG 19
5
24
21%
GoogLeNet
14
74
19%
* Общее количество уровней = Свертка (включая FC) + Объединение + LRN
Исходя из процентного содержания уровня пула, весьма вероятно, что субблок планарной обработки большую часть времени простаивает. {\ beta}} \]
Форма локальной области всегда \ (1 \ умножить на 1 \ умножить на \).{2} \) и \ (\ text {Source} _ {w, h, c} \ times f (x) \) можно обойти с помощью программирование соответствующих регистров так, чтобы CDP можно было рассматривать как функция автономной таблицы поиска (LUT).
Для RESMO принят подход таблицы поиска. (обратная операция-экспонента-сумма-множественная операция) \ (f \ left (x \ right) \).
Рис.72 Кривая для операции обратная экспонента-сумма-множитель
На следующей схеме показаны внутренние блоки обработки данных канала. субблока и подключения к другим субблокам.Диаграмма предназначена только для захват идей и не представляет фактические границы и иерархии модулей RTL.
Рис.73 Блок-схема кросс-канальной обработки данных
Субблок обработки канала всегда работает независимо от других подузлы обработки. Он получает входные данные и отправляет выходные данные в PDMA. Из-за ограничений доступа к памяти последовательность входных данных в определенных заказах. Последовательность ввода показана ниже. диаграмма, а выходная последовательность такая же, как входная.
Рис.74 Последовательность ввода / вывода обработки канала
В следующей таблице показаны параметры уровней LRN в текущих хорошо известных сетях.
Таблица 55 Сводка параметров уровня LRN Сеть
Общий номер уровня LRN
Номер местного размера
Альфа
бета
AlexNet
2
5
0.0001
0,75
Превышение точности
0
NA
0,0001
0,75
VGG-19
0
NA
0,0001
0,75
GoogLeNet
2
5
0.0001
0,75
Элементы данных на краю полосы могут использоваться соседними полосами. Эти данные необходимо буферизовать, номер записи буфера должен быть \ (\ left \ lbrack \ text {Max} \ left (\ text {loca} l _ {\ text {regio} n _ {\ text {size}}} \ right) — 1 \ right \ rbrack \ times 8 = 7 \ раз 8 = 56 \ байт \).
Оценка размера буфера
В субблоке многоканальной обработки данных есть три основных буфера: LUT в блоке активации, чтение буфера DMA и запись буфера DMA.Размер LUT то же, что и SDP (644 байта).
Для буфера DMA чтения есть два ограничения для определения его размера. Первый — покрыть задержку доступа к системе памяти. Предположение 128 циклов. Другой — пропускная способность доступа. Случай максимальной производительности — 8 Байт на цикл (8 элементов в int8, 4 элемента в int16 / fp16), поэтому чтение Размер буфера DMA равен \ (128 \ times 8 = 1 Кбайт \).
Рассмотрение мощности
Цели субблока обработки данных канала для уровня LRN в NVDLA 1.0. На основе анализ существующих сетей, использование обработки каналов низкое.
Таблица 56 Процент местного уровня реагирования Сеть
Общий номер уровня LRN
Общее количество слоев *
В процентах
AlexNet
2
13
15%
Превышение точности
0
12
0%
VGG 19
0
24
0%
GoogLeNet
2
74
3%
* Общее количество уровней = Свертка (включая FC) + Объединение + LRN
На основе процентного содержания слоя нормализации местного отклика субблок обработки данных канала большую часть времени будет бездействовать.Следовательно, конструкция поддерживает синхронизацию устройства.
РУБИК
Обзор
МодульРУБИК аналогичен BDMA. Преобразует формат отображения данных без расчета данных. РУБИК имеет 3 режима работы, это:
Поскольку функция модуля заключается в преобразовании кубов данных признаков, мы называем его РУБИК. Блок.
Фиг.75 РУБИК
Контракт
Уровень программной деконволюции всегда использует несколько HW-слоев или две фазы. На этапе I результат генерируется конвейером свертки.А вторая фаза договорный режим от РУБИК.
Обычно слой SW деконволюции имеет шаг деконволюции x и y шаг, превышающий 1. И с этими шагами выход HW-уровень фазы I — это куб данных с расширенным каналом. Договорный режим в РУБИК преобразует формат отображения, чтобы уменьшить размер куба. На рисунке ниже показан Пример переназначения, где шаг x равен 2, а шаг y равен 3.
Рис.76 Контрактный режим в РУБИК
Формула размера входного куба и выходного размера:
\ [W ^ {‘} = W * деконв \ _ x \ _ шаг \]
\ [H ^ {‘} = H * деконв \ _ y \ _ шаг \]
\ [C ^ {‘} = \ frac {C} {deconv \ _ x \ _ stride * deconv \ _ y \ _ stride \} \]
Двигатель RUBIK сжимает слой за слоем.Требуется один входной срез Wx1xC и преобразует его в выходной субкуб W’xH’xC ’. Затем он переходит к следующему входному срезу. Он никогда не отправляет запрос через границу строки.
При выполнении контракта начальный адрес ввода / вывода и шаг строки выравнивается по 32 байтам. Он всегда пытается отправить 256-байтовые запросы. В эффективность памяти составляет от 80% до 100%, что зависит от запуска адрес. Если весь шаг адреса и начальный адрес выровнены по 256 байт, КПД памяти достигает 100%.
Требование договорного режима:
\ [C \ \% \ \ left (\ text {decon} v_ {x _ {\ text {stride}}} * deconv_ {y _ {\ text {stride}}} * 32 \ right) == 0 \]
Каждое измерение куба входных и выходных данных, например ширина входных данных, ширина выходных данных, размер входного канала, не должна превышать 8192 в одном слой контракта.
Разделить и объединить
Разделение и объединение — два противоположных режима работы в РУБИК. Трещина преобразует куб данных в M-планарные форматы (NCHW). Количество самолетов равен размеру канала. Режим слияния преобразует серию самолетов в куб данных функции. Преобразование показано на рисунке ниже.
Рис.77 Режимы разделения и объединения в RUBIK
M-планарный формат похож на форматы изображений. Это шаг линейный формат, содержащий данные T_R16_I, T_R8_I или T_R16_F.Каждый самолет содержит только 1 канал данных или один элемент. Линия шага и планарный шаг всех плоскостей (M-планарный) должен быть выровнен по 64 байтам. Это в отличие от других форматов данных для NVDLA.
Рассмотрение мощности
Блок РУБИК применяет синхронизацию в тракте передачи данных. Часы данных путь РУБИК закрывается, когда агрегат находится в режиме ожидания и нет доступного HW-слоя из программируемые регистры.
.